

| 导读 | 作为线上+线下的电商零售平台,国美互联网如何将人工智能技术嵌入到实际业务中?机器学习和深度学习技术为国美带来了哪些改变?在这火热的时局中,国美未来在前沿技术方面又将如何布局? 且听下文一一分解。 |
今年机器学习已然成为炙手可热的技术话题。深度学习与人工智能技术正在改变人们的生活,同时也给企业管理大量数据、为用户提供更精准的服务提供了一些新的思路和尝试的方向。越来越多的企业开始尝试将机器学习引入原有的大数据平台和框架中,并将公司业务与机器学习、深度学习技术相结合以寻求更优的业务价值。
2016 年 11 月国美互联网板块所属国美在线、美信、国美管家、GOME 酒窖、国美海外购整合组建国美互联网生态(分享)科技公司(下面简称国美互联网),并推出了国美 Plus APP。作为具备线上线下双重基因的新零售平台,国美互联网近年来,针对机器学习、深度学习技术与社交电商业务相结合进行了一系列尝试和创新。这次我们非常有幸对国美互联网大数据中心的副总监杨骥进行了采访,目前他主要负责搜索、推荐和深度学习三个方向的研发工作及团队管理。作为国美互联网个性化推荐团队和算法架构平台建设者,杨骥与我们分享了国美互联网在机器学习技术之路上的尝试、挑战与收获。
国美互联网大数据中心主要负责大数据平台运维、大数据应用、BI、搜索、推荐等相关内容,支撑国美互联网全业务线(包括大家电、百货、汽车等)的精准营销和数据变现。尤其是最近几年以来,中心在机器学习方面投入了非常多的资源,除了升级推荐和搜索相关的机器学习算法之外,还陆续推出了“国美拍照购”、“图像相似推荐”、“图像搭配推荐”等基于深度学习算法的产品。
对于电商来说,个性化推荐系统是不可或缺的利器,也是国美互联网应用机器学习和深度学习技术的主要战场。
推荐系统演进之路
要将机器学习技术应用到实际产品中,必然离不开一套良好的算法和平台架构。2016 年 3 月杨骥加入国美之后,对机器学习和深度学习算法以及线上服务架构进行重构,打造了全新的个性化推荐系统。目前,杨骥带领团队已经完成了三轮大规模的架构升级,最终实现了一套完整的推荐系统架构,其中包括机器学习和深度学习计算平台,并整合了 A/B 测试、线上部署和自动化监测等功能。
下面是国美互联网应用 Learning to Rank(机器学习排序,L2R)后的推荐系统流程图和架构图。采用的工具包括 Apache Storm、Kafka、Spark、Flink 等。
图 1:流程图
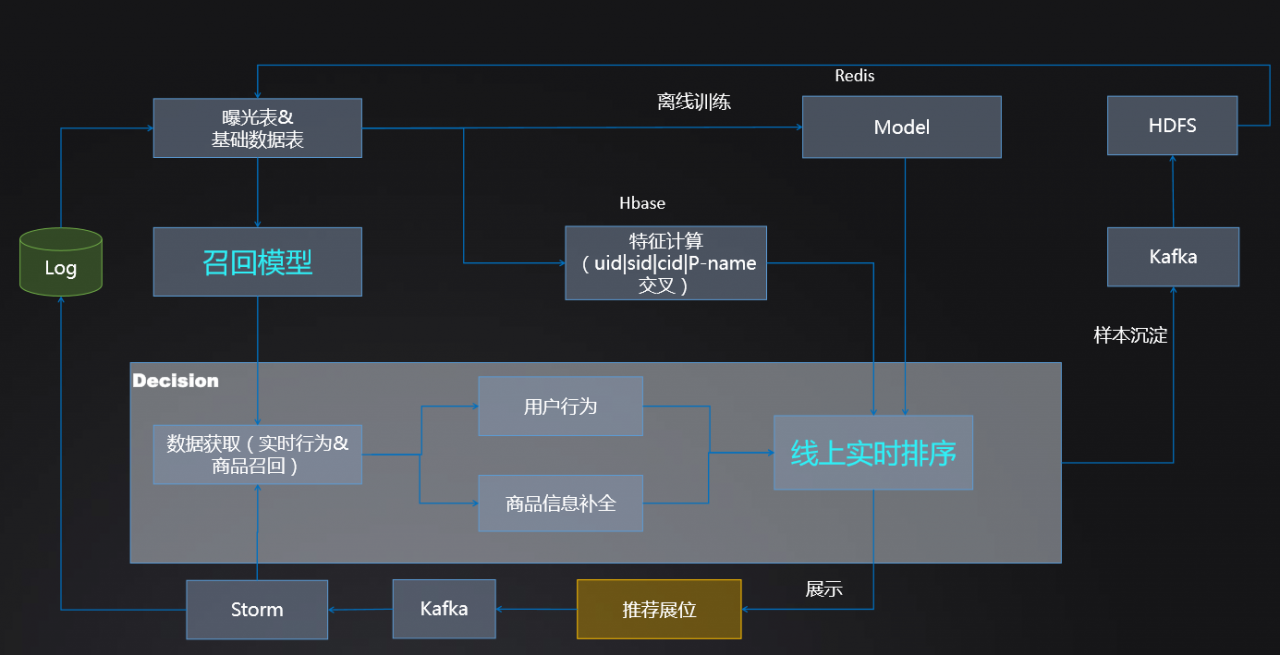
图 2:架构图
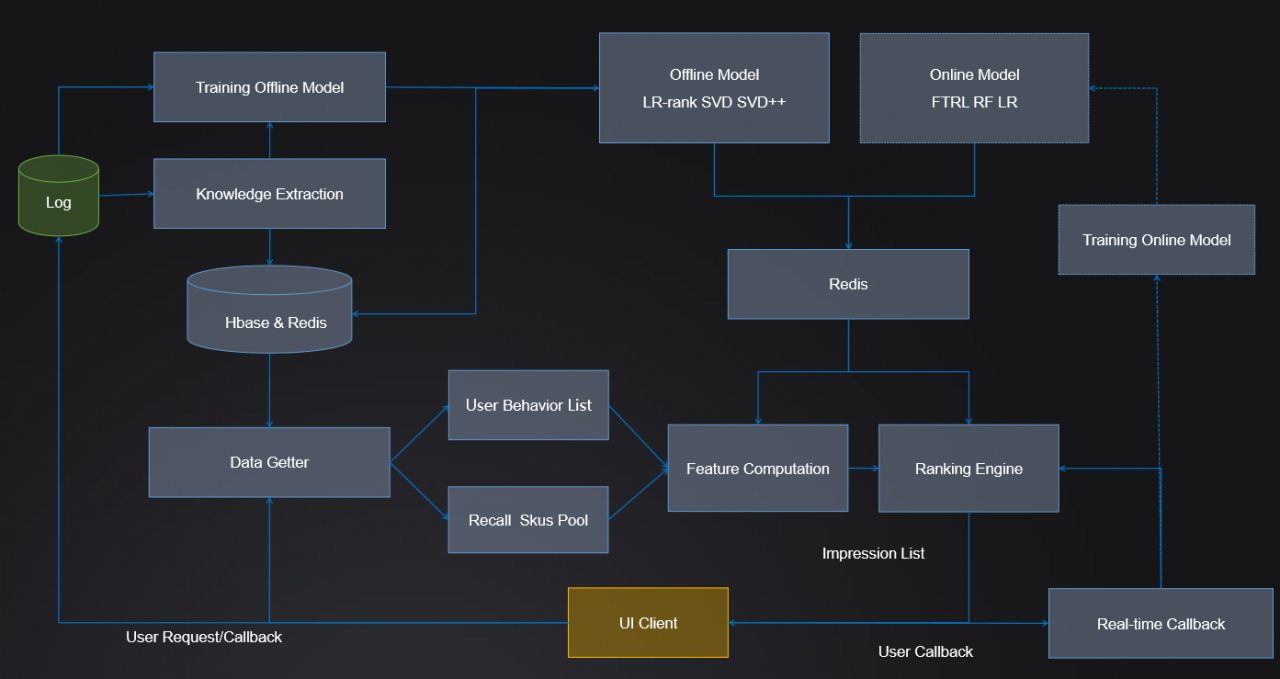
当用户在网站或者 APP 上看到“猜你喜欢”的商品后进行了点击。一方面,该点击信息通过实时数据处理系统反馈给排序引擎和在线训练模型,帮助推荐系统实时调优;另一方面,点击信息进入 Log。基于 Log 进行知识挖掘,获取相关特征和训练数据,并进行基础推荐模型的计算(如关联规则和协同过滤模型等)以及离线排序模型的训练。离线排序模型缓存到 Redis 模型服务器,而相关特征数据、基础推荐模型的粗筛结果缓存到 Hbase 和 Redis 数据服务器。
系统要向用户展示推荐商品时,数据获取模块获得用户的基本特征和推荐的初筛结果,进行交互特征和在线特征的计算,然后利用离线模型、在线模型以及业务规则进行最终的筛选与排序,返回最终推荐结果给用户。
国美使用 Apache Kafka 和 Apache Storm 系统收集和处理推荐展位上的实时数据消息,包括推荐展位每页已经展示过什么商品、用户点击了什么商品等。然后对这些数据消息进行实时分析和统计,包括用户在推荐展位展示之前已经对哪些品类的产品有过购买行为,对不同的已购买商品赋予不同的权重(比如手机买过则短期不会再买,纸巾则会隔较短时间反复购买),再计算出接下来的推荐展位应该显示哪些商品。
对于一些特殊的用户数据需要进行数据清理,以免影响算法模型的拟合效果。比如,已购买用户对同一商品的点击和查看对推荐排序模型是无用的,应该被排除;还有一些用户频繁地点击商品但却不下单,被称为“点击狂人”,可以通过统计方法将其剔除。
国美互联网的推荐系统中离线模型和在线学习相辅相成。
离线模型主要是为了节省计算时间、加快响应速度,当然需要消耗一些缓存空间并牺牲一定的精度。例如,召回模型中会预置一些算法模型,并根据快照信息离线进行商品的初筛,使进入实时排序模型的商品量从千万级别减少为数百个,大大提高了实时排序的效率。目前国美互联网的召回模型中有 20-30 个算法模型,既保证了召回的多样性,也不至于给维护带来太多麻烦。
而在线学习则是为了提高排序的准确度,它能根据用户实时的行为数据对模型进行实时训练,使当前模型准确地反应用户当下的兴趣和倾向。但是使用在线学习也会引入新问题,比如在电商店庆日,用户的购买行为可能是非理性的,如果一味地使用在线学习将会给算法模型引入严重的偏差,因此国美的推荐系统会定期(每天或每隔几个小时)使用离线数据进行模型训练并对在线模型进行校准。
对于电商来说,内部收集到的用户数据用来做用户画像肯定不如社交类网站的数据丰富,可能导致做出来的用户画像不够立体。因此国美互联网通过将用户行为映射到商品信息上来构建用户画像。比如用户行为(点击、关注或收藏等)涉及的一系列商品的属性(比如品类、品牌、中心词、价格等)作为用户行为的映射,刻画出用户感兴趣的商品,然后再结合用户标签(比如有车一族、户外运动爱好者等),完成用户画像的构建。目前用户画像在国美互联网主要用于商品召回和最终商品推荐时的过滤。
对于个性化推荐排序来说,设定可量化的目标是非常重要的。
国美对算法的评估方式包括离线评测、在线 A/B 测试和算法覆盖率测试。离线评测常用的评估指标为 AUC、Logloss 和 NDCG,其中 AUC 和 Logloss 主要评估分类的准确率,而 NDCG 则是评估排序质量的指标。
国美互联网采用 CTR/CVR/GMV 来对推荐排序算法的实际效果进行评估。与传统的推荐方法相比,使用机器学习和深度学习技术后的个性化推荐排序给国美互联网的 GMV、点击率和转化率都带来了更为显著的提升。
2017 年以来,凭借深度学习技术,离线模型和实时排序模型的质量大幅提升,尤其是 1-5 月份与 2016 年 1-5 月份相比提升效果十分显著,推荐 GMV 提升 70%、参与转化率 CVR 提升 100%。而 CTR 也有一组数据可供参考,采用个性化排序后,PC 订单页“猜你喜欢”展位 CTR 提升幅度 30.79%,PC 首页“猜你喜欢”展位 CTR 提升幅度 14.16%。
大数据+机器学习& 深度学习技术的力量着实惊人。
自 2012 年 ImageNet 大赛技惊四座后,深度学习已经成为近年来机器学习和人工智能领域中关注度最高的技术。
国美互联网也展开了深度学习在图像识别中的研究,并且已经应用于国美 Plus 的拍照购功能,它可以根据用户上传的图片预测品类,推荐相关商品。
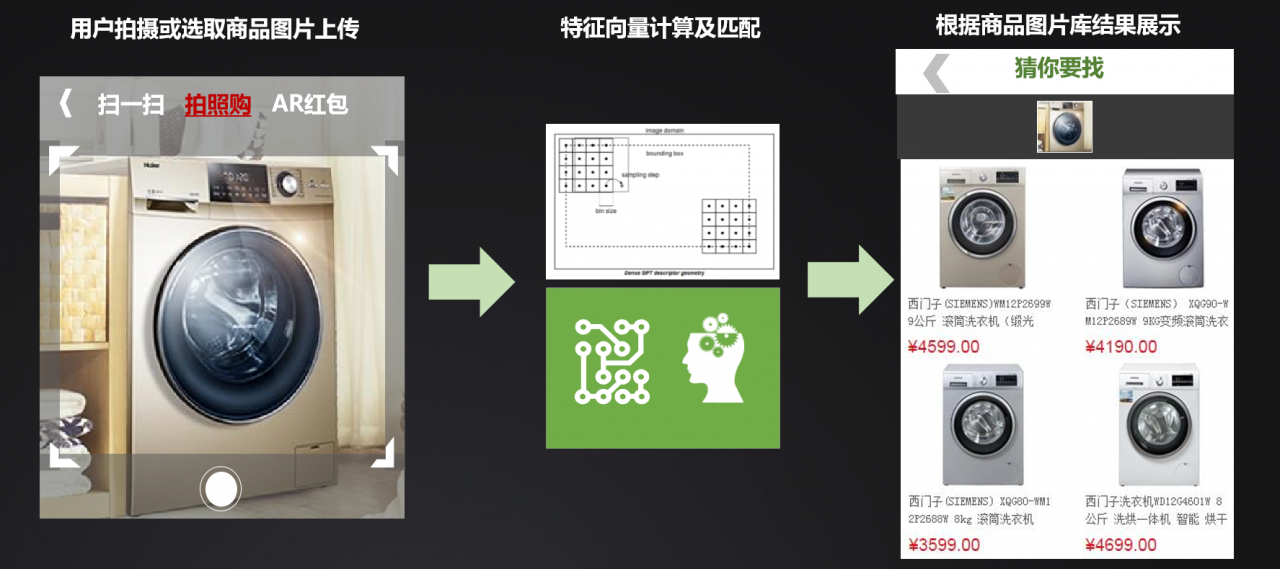
当用户拍照或者从 PC 和手机选取商品图片上传成功以后,系统就会进行特征向量的计算及匹配。然后猜测用户想要的商品,根据商品图片库的相关结果进行展示。

图像检索流程可以分为四步,分别是图像标注、提取特征、降维和匹配检索。
图像标注:对国美全站的商品图像进行标注,最主要的工作是数据清洗,即把不能和品类对应的图片删除或者重新进行品类校准;先统计国美全站最近一年内各品类下商品总数的分布,然后按照分布进行图片抽样。
提取特征:图片的特征分为通过深度学习得到的特征和图像局部特征。可利用 caffe 对 CNN 进行训练,将倒数第二层输出作为 Feature Learning 的结果提取出来 (Deep Learning + Transfer Learning);可利用局部特征算子 (SIFT、kaze 等) 提取出图像的局部特征。
降维:用积量化等方法对深度学习特征和图像局部特征进行编码和降维。
匹配检索:采用最近邻搜索的方法找出每一个商品的相似商品集合。
基于拍照购,国美还将图像识别融合到了个性化推荐、相似推荐和搭配购推荐中
用户行为+商品内容=更精确的推荐
杨骥认为,电商领域传统的基于用户行为构建个性化推荐系统存在一定的局限性。
基于用户行为的推荐系统以用户的浏览、点击、收藏、关注、加入购物车、下单等行为作为数据基础,来分析用户可能的购物倾向。对于用户来说,从进入网站或 APP 开始浏览商品、到考虑是否购买、最终到下单是一个连续的过程,但对于算法工程师来说得到的只是日志中几个离散的记录,信息量严重不足,通过这些有限的信息难以推测用户完整的购物决策过程。杨骥认为,除了用户行为,还应该重点考虑商品的内容(比如商品信息主图、商品详情页图片、标题、广告用语和风格等)能够对用户产生多大的冲击。目前国美互联网推荐团队的工作更多地侧重于内容方面。
国美互联网搜索推荐团队利用深度学习技术(如 CNN 卷积神经网络、目标检测等)对商品主图、详情页图片进行分析和描述,将图片(非结构化数据)转成文字(结构化数据)并存放到数据库里,以便后续分析时调用。他们由此构建了一个基于图像识别的相似召回模型,将其与基于用户行为的召回模型融合在一起,在此基础上进行线上交互。如此一来得到了更多刻画用户、刻画商品的维度,提升了召回模型的精准度和多样性,效果优于仅仅关注用户的点击、关注、购买等行为。
“推荐系统并非 0 和 1 的问题,而是要最大化用户购买概率。先满足 80%用户的大体需求,然后再对 20%的用户进行精细的需求雕刻。”
利用机器学习和深度学习构建推荐场景时,最大的难点是数据源头,而深度学习对训练数据量要求很高,并不是每个机器学习问题都有足够多的训练数据。因此国美也尝试将深度学习与迁移学习(Transfer Learning)结合起来。
仍以拍照购功能为例,拍照购涉及到图像相似性检索的问题。而已经有很多人针对已有的海量数据训练出了不同任务场景下的模型,因此我们可以借助别人训练好的模型,在国美互联网商品库中再次训练并进行精调,使模型达到应用所需的要求。
目前,国美大数据中心正在进行国美深度学习云平台(Gome CloudDL)的开发,使之能够支持各业务线在风控、图像分类、自然语言处理、人脸识别、推荐、搜索、广告等场景下的需求。Gome CloudDL 基于 TensorFlow 和 Docker 搭建,能够实现多任务资源的隔离、基于 Kubernetes 的调度、模型的持久化存储、TensorFlow 与 Spark 无缝集成等功能。
拍照购项目会继续在图像分割、实拍图处理、深度学习模型压缩、分布式搜索等方面进行优化,提高召回精度。
除了在召回模型中使用 CNN,我们接下来会尝试利用 RNN 来“捕捉”用户在点击序列中的模式,即利用用户点击行为发生先后顺序进行推荐和搜索的展示排序。同时还会进行深度强化学习(Deep Reinforcement Learning)的算法开发,根据用户所处的场景,在交互的过程中动态地推荐商品、活动、主题等,将传统的“商品推荐”升级成“场景式推荐”。
国美互联网大数据中心如同人工智能技术在国美的一片试验田,还有更多创新项目将在这里孵化。未来道阻且长,但探索的脚步不会停下。
杨骥 ,国美互联网大数据中心副总监。毕业于中国传媒大学并获得博士学位,博士阶段研究方向主要是计算机视觉和机器学习,包括图像的目标识别和语义分割。先后任职于凡客、京东,曾是京东 PC 首页与 APP 首页个性化推荐的开发者。多年来致力于个性化推荐系统与算法的研究和实践,目前专注于社交电商领域的深度学习技术。
原文来自:http://www.infoq.com/cn/articles/depth-learning-build-accurate-recommendation-system
本文地址:https://www.linuxprobe.com/learning-ai-guomei.html编辑:周阳,审核员:逄增宝
本文原创地址:https://www.linuxprobe.com/learning-ai-guomei.html编辑:public,审核员:暂无







