

| 导读 | 在实现企业敏捷性与微服务 API 管理上,学习如何进行 API 管理可以支持更好的集成,与 3scale 一起给你带来更好的合作。 |
在这些日子里,好像每个人都进入了微服务,与此同时,庞大的架构正在坍塌,就像老旧的被抛弃的城堡。
公众的注意力聚集在趋势上时,常常会被夸大不能真正反映实际中的情况,但是,这一次,感觉像是一个共识。微服务迭代在关注点上基本分离了,表达一个在名字上的见解来自于工程师团队,他们精心设计需要解决的实际问题。
在这篇文章中,我们将扮演魔鬼的支持者,分享来自社区的和来自用户的一些见解,在生产的微服务中检查上面的问题——以及我们如何解决他们。
关注分离不是一个新的概念,其计算是分布式的。它的好处是巨大的,但是也付出了代价,这通常意味着在时间和金钱上更高的运维成本。混合它们两者,你可以在一个培养皿中发现各种各样的问题。把它放在生产中,问题就会成倍增长。用调试来救援,那么,等着吧……调试不会让问题消失。
正如Bryan Cantrill在QCon会议中指出的那样,“调试变成了口口相传的传统,童话故事的问题是它们怎么消失的。”而实际上,它更像一门科学,理解系统是如何工作的,而不是我们所认为的那样。
调试不是一个次要的任务,它是一个根本的问题。Sir Maurice Wilkes 说,在第一个项目的创建时就需要调试器,并且要意识到它对于开发人员的调试将发挥重要的作用:
"在 1949年,我们就开始了编程,令人惊异的是,编程不像我们认为的那样容易正确。调试必须被发现。我记得那一瞬间,当我意识到我生活的很大一部分就是在我自己的程序中发现错误。”
我们被训练成只是使问题消失,这样也只是使问题消失罢了。理解系统到底是如何工作才是真正的挑战。
不管你是逐渐划分整体程序来做到精确服务,还是建立一个全新的系统,现在你拥有了更多的监测服务。每一项服务类似于一下几点:
- 使用不同的技术或语言。
- 依靠不同的机器或容器。
- 使用其特有的版本控制。
重点是,据监测,该系统变得高度分散,一个更强大的需要为了集中监控和日志记录产生 ,其目的是有一个公平的监测记录以了解发生了什么。
例如,最近的一个持续的博客讨论中,一个脚本被描述为一个坏场景,需要重复回滚。主要是一个简单的程序整体。不过,我们现在有了微服务。因此,我们需要确定哪些服务需要回滚,回滚对其他服务的影响是什么,或者也许我们只需要添加一些容量,结果只是把问题顺推到下一服务。
如果你想监测整体架构是困难的,这需要10倍使用微服务的努力,还需要提前规划的更大的投资。
记录、记录、记录。大量的非结构化文本由服务器按每天的进程生成。IT中的二氧化碳等效物放在硬盘里,也耗用了Splunk账单/ELK存储成本。
在一个整体的架构中,你的记录可能已经分散在不同的地方——即使有一个整体的思维倾向,你可能不得不使用一些不同的层,这些不同的层可能记录到不同的地方。使用微服务,你的记录会打破进一步下降。现在,当研究与某些用户事务相关的场景时,你不得不将所有不同的记录从所有可能已经运行了的服务中拉出来,以了解错误所在。
在Takipi中,我们团队使用基于Takipi解决了这个问题。由于所有的记录错误和警告都来自于产品JVMs,我们注入了智能链接到记录,这些智能链接将连带出对事件的分析。包括其在每一个框架里的完整的堆栈跟踪,即使它被分配在多个服务/机器。
微服务都是关于将程序分解成独立组件。作为其副作用,行动程序和监控也会被分解到每一个服务,并失去整体系统的运转。这里的挑战是使用适当的工具集中这些分散的小块。
在一个特定的服务中,如果你遵循一些坏掉的事务,那么你将不能保证相同的服务各司其职。让我们假设你的服务之间有一些消息传输机制,像RabbitMQ, ActiveMQ 或者可能是 Akka。
有几个可能的场景,尽管服务行为表现如预期的那样,没有问题被发现:
- 输入接收是坏的,你需要理解是什么让先前的服务表现失常。
- 接收方返回的结果是一些预期之外的回应,你需要理解下一个服务行为是怎么样的。
- 极有可能的场景是这些依赖比1对1更复杂,那该怎么办?或者有超过一个服务,那这个服务对解决问题有什么好处?
无论问题是什么,第一步就是要理解微服务,在微服务中寻找答案。数据是分散在各地的,并且可能根本就不会存在于你的日志和前端仪表显示中。
与庞然大物相比,通常你是知道你正在寻找正确的方向前进的。而微服务让你从你获取的数据中更难理解问题的来源。
好了,让我们开始正式研究调查。现在的出发点是,我们已经锁定了有问题的服务,把所有的数据有对栈的痕迹和一下变量值从所有的记录中提取出来了。如果你有APM(如New Relic、AppDynamics或Dynatrace,我们本文写到的和这里所提到的),你也可能会得到一下关于异常处理时间的一样的方法/做一些基本的问题严重程度评估的数据。
但是,实际的问题怎么样呢?实际导致问题的根源?实际已经被破解的密码。
在更多的情况下,你最开始满怀希望地从记录在提取的一部分可变数据,可能不是移动箭头的那些数据。它们通常会导致下一线索,这就需要你去发现更多,并添加一个或两个其他的记录描述。部署的变化,希望这个问题不再次发生,因为有时只是添加一些记录描述似乎可以解决问题。
当问题的根源在微服务中跨越多个服务时,其关键是在其中找到一个集中的根源监测工具。
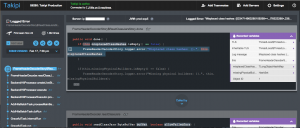
Takipi的问题分析仪表盘——变量值覆盖在实际代码堆栈中的每一帧
在持续讨论的博客中谈及到的另一个产品,我们在这里想强调的是,从一个在典型架构图的层模型到一个具有微服务的图模型。
这儿可能会发生两个问题,与检测中保持你的依赖有关。
1、假如你有一个循环依赖在你的服务之间,当一个特定事务被困在一个循环体中时,你很容易抛出分布式堆栈溢出的错误异常。
2、假如两个服务共享一个依赖,你以某种方式更新其他服务的API会影响它们,那么你需要马上全部更新一遍。这就引发问题了,比如你先更新哪个?如何去保证一个安全事务呢?
越多服务意味着它们每个不同的发布周期,会增加复杂度。复制一个问题是非常困难的,尤其是在一个新的版本中。
在一个微服务结构中,你更容易遇到错误来自依赖的问题。
马上调试使得你犯错的心态消失——这是字面直接调试的意思。当你在脑海中思索系统的环境,有更多的特设问题需要解决。这是有关于从全局层面去理解系统,是什么使得它运行,事情是如何与你期待一样去发展。
最后一点,全都是有关你所使用的工具与你操作的工作流程。
原文来自:http://www.linuxeden.com/html/news/20160816/167543.html
本文地址:https://www.linuxprobe.com/micro-services-challenges.html编辑员:杨帆,审核员:冯琪
本文原创地址:https://www.linuxprobe.com/micro-services-challenges.html编辑:public,审核员:暂无







