

| 导读 | 磁盘坏道、断电等意外不是常态,但遇上了就足够你“惊心动魄”!如果是数据库损坏造成的数据丢失,Binlog也不可用了,怎么办?为了在短时间内无损恢复数据以保证业务稳定性,除了利用binlog,我们还修炼了一招新的恢复技能! |
还记得我们之前写过的《只需一招,让失控的研发爱上你》吗?前文提到过我们日常使用的比较多的两种数据库恢复方法是:
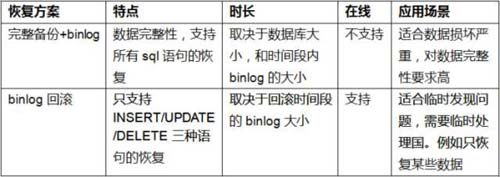
以上两种方法都可以实现实时性的回档,但是你会认为有了这两种技能就够了吗?
不….!
在线上这种错综复杂的架构中,其实还有很多未知的原因,我们是没法预知的。例如以下这种情况:
因辛勤劳动而折寿的磁盘产生成长坏道,导致数据库损坏。而又刚好损坏了ibdata文件和binlog文件。那么如果还想着以定时备份+binlog恢复的方案就不可能了,难道只能用定点备份回档吗?深思熟虑后,作为一名运维人员,我们是绝对不会在万不得已的情况下实行有损回档,因为这对业务产生太大的影响了,但是除此之外又能怎么办呢?下面我们将要放一门大招!!!
首先检查数据库环境,是否开启了独立表空间,如果已经开启的话,那恭喜你,有很大的机会可以恢复全部数据。我们可以依赖每个数据库目录下的frm和ibd文件来实现数据恢复,一般来说如果使用了InnoDB但没开启独立表空间的话,所有的数据库表信息和元数据都会写入ibdata文件里,这样长久运行的话,ibdata文件会变得越来越大,数据库性能下降。InnoDB提供了开启独立表空间参数,可以让数据独立存放起来,这样子ibdata文件只用于存放一些引擎相关的索引信息,实际的数据写入到独立的frm和ibd文件里。
好,有了frm和ibd文件,我们可以开始尝试数据恢复了,他的过程比binlog还原既惊险又有趣!首先我们来看一下关于ibd和frm的说明:
.frm文件:保存了每个表的元数据,包括表结构的定义等,该文件与数据库引擎无关。
.ibd文件:InnoDB引擎开启了独立表空间(my.ini中配置innodb_file_per_table = 1)产生的存放该表的数据和索引的文件。
我们都知道,对于InnoDB的数据库,如果不把整个数据目录拷贝,只拷贝指定数据库目录到新的实例下,数据库是认不出来的。那么如何根据这两个文件还恢复数据库呢?
由于ibdata文件上存放了一些关于引擎的索引信息,ibdata文件损坏导致表名索引丢失而无法启动。那么我们可以先把原来旧的整个数据目录改名备份,然后重新初始化数据库生成新的ibdata文件,然后重新创建原有的数据库以及对应的表,最后把备份的表空间id号改为新建的表空间id号(ibdata文件里有每个表唯一的表空间索引id,该id由创建新表的数量依次递增),这样就可以恢复原来的数据库了。
举个例子:
库名:test_restore
表结构:db_struc.sql
表文件:G_RESTORE.ibd、G_RESTORE.frm
#mysql -uroot –p**** -e “create database test_restore”
#mysql -uroot –p**** test_restore < db_struc.sql
#vim -b /data/database/mysql/test_restore/G_RESTORE.ibd
直接打开为乱码,转成16进制查看。Vi中执行 :%!xxd 转化为16进制。结果为 :

如图所示。G_RESTORE表在mysql数据库中的id为00fe。
修改备份的G_RESTORE.ibd文件。操作同上,注意需先备份。
#cp G_RESTORE.ibd{,_back}
#vim -v G_RESTORE.ibd

将011b修改为00fe 。注意。修改完成后需要在vim中先执行 :%!xxd -r
再wq 保存退出文件。不然保存到的是16进制查看的结果。
保存结果如下:

将修改好的G_RESTORE.ibd 替换掉新数据库中的G_RESTORE.ibd文件。
关于ibdata表id的解释:

参考官方文档解释,每个表空间分配了4个字节存储了表空间id信息,最后偏移量地址为38。还有一组预留的表空间id,同样是4个字节,最后偏移量地址为42。
关闭mysql。修改my.conf。
innodb_force_recovery=6 innodb_purge_threads=0
启动数据库。如果不修改。数据库会认为G_RESTORE已被损坏。
Select 一下,即可查看到还原结果,但此时插入数据会报错,应尽快将数据dump出来 ,导回原来的实例中。
导出数据,再导入数据,恢复完毕!
#mysqldump -uroot –p****** test_restore > test_restore.sql #mysql -uroot –p****** test_restore < test_restore.sql
说明:变更了新的space id后的.ibd表文件,启动数据库后只能认出数据,但不能写入,这是因为原ibdata文件不仅保存了space id索引,还同时保存了一些其它的元数据。为了使元数据补全,所以采取导出、再导入的操作。
以上举例为单个库表的恢复过程,看到这里大家一定会产生另一个疑问吧?线上的场景不可能是只有一个表的,数据库表很多的情况下,这样一个个表的修改,速度无疑是太慢了。那么存在大量表的情况下如何恢复呢?思路是,取得备份的ibd文件的id值,按id值顺序来建表,中间跨度随便建表语句来凑够数(每个表空间索引id由创建新表的数量依次递增)。实现方式如下:
1. 获取备份数据库ibd文件的space id号,并排序。
for ibd in `find test_restore/ -name “*.ibd”` ; do echo -e “${ibd///// } /c” ;hexdump -C ${ibd} |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’ ;done | sort -n -k 3 | column -t > /tmp/
生成的ibd.txt文件,格式如下:(库名–表名–SpaceId)

2. 新建表,查看当前表空间id(假设space id为10)
#mysql -uroot –p****** -e”create table test.tt(a bool)”
#hexdump -C mysql/test/tt.ibd |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’
3. 先创建所有库,准备所有表结构,写脚本,依据space id号自动创建新表
准备好数据库表结构,可以从备份文件里取出来(我们备份方式是把结构和数据分开备份的),或者从其他有相同表结构的服务器上备份再拷贝过来。
参考备份语句:
mysqldump -uroot –p****** -d ${db} –T /data/backup/${db}/
创建原有的数据库:
mysql -uroot –p****** -e “create database ${db}”
恢复表id创建表脚本:
#!/bin/bash
#因为前面假设为10,所以从11开始创建
oid=11
#打开前面生成的ibd.txt文件,按行读取”库名–表名–SpaceId”
cat /tmp/ibd.txt | while read db tb id ;do
#假如我们需要恢复catetory表,他的id为415,基于id是创表自增的原则,即415-11=404,
#我们还需要循环创建404个表后,才真正导入catetory表结构。
for ((oid;oid<id;oid++)); do
mysql -uroot –p****** -e “create table test.t(a bool);drop table test.t;” && echo “${oid} ok”
done
#循环创建404次表后,id为415,与原来备份的.ibd文件编号一致,导入表结构
mysql -uroot –p****** ${db} < /data/backup/${db}/${tb%%.ibd}.sql && echo “${oid} ${db}/${tb%%.ibd}.sql ok”
let oid=oid+1
done
4. 检查表空间id 和备份的是否一致
for ibd in `find test_restore/ -name “*.ibd”` ; do echo -e “${ibd///// } /c” ;hexdump -C ${ibd} |head -n 3 |tail -n 1|awk ‘{print strtonum(“0x”$6$7)}’ ;done | sort -n -k 3 | column -t > /tmp/ibd2.txt
确认一致后,拷贝备份的.ibd文件到新数据库实例目录下,修改my.cnf
innodb_force_recovery=6
innodb_purge_threads=0
启动数据库。后续步骤如同单表恢复,直接导出恢复到原来实例中即可。
当然,这种方式是在数据库出现极端情况下,不得不采取的一种方式,线上最重要的还是做好主从同步和定时备份,从而规避此类风险。
使用过MySQL的同学,刚开始接触最多的莫过于MyISAM表引擎了,这种引擎的数据库会分别创建三个文件:表结构、表索引、表数据空间。我们可以将某个数据库目录直接迁移到其他数据库也可以正常工作。然而当你使用InnoDB的时候,一切都变了。
InnoDB默认会将所有的数据库InnoDB引擎的表数据存储在一个共享空间中:ibdata1,这样就感觉不爽,增删数据库的时候,ibdata1文件不会自动收缩,单个数据库的备份也将成为问题。通常只能将数据使用mysqldump导出,然后再导入解决这个问题。
但是可以通过修改MySQL配置文件[mysqld]部分中innodb_file_per_table的参数来开启独立表空间模式,每个数据库的每个表都会生成一个数据空间。
1.每个表都有自已独立的表空间。
2.每个表的数据和索引都会存在自已的表空间中。
3.可以实现单表在不同的数据库中移动。
4.空间可以回收(除drop table操作处,表空不能自已回收)
a) Drop table操作自动回收表空间,如果对于统计分析或是日值表,删除大量数据后可以通过:alter table TableName engine=innodb;回缩不用的空间。
b) 对于使innodb-plugin的Innodb使用turncate table也会使空间收缩。
c) 对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
单表增加过大,如超过100个G。
共享表空间在Insert操作上少有优势。其它都没独立表空间表现好。当启用独立表空间时,请合理调整一下:innodb_open_files。
配置方式:
1.innodb_file_per_table设置.开启方法:
在my.cnf中[mysqld]下设置
innodb_file_per_table=1
2.查看是否开启:
mysql> show variables like ‘%per_table%’;
3.关闭独享表空间
innodb_file_per_table=0关闭独立的表空间
mysql> show variables like ‘%per_table%’;
原文来自:http://www.yunweipai.com/archives/19844.html
本文地址:https://www.linuxprobe.com/mysql-recovery-data.html编辑员:郭建鹏,审核员:逄增宝
本文原创地址:https://www.linuxprobe.com/mysql-recovery-data.html编辑:roc_guo,审核员:暂无







