

| 导读 | 业界运维圈子的童鞋都有这么个共识,运维真是一种苦逼的生活了,不仅繁杂多样变幻多端,整个生态链涉及网络、系统、安全、数据库等战线极长极长,关键在其中某些环节,还有Ta在不断的搞事,搞事,搞事 |
业界运维圈子的童鞋都有这么个共识,运维真是一种苦逼的生活了,不仅繁杂多样变幻多端,整个生态链涉及网络、系统、安全、数据库等战线极长极长,关键在其中某些环节,还有Ta在不断的搞事,搞事,搞事,(神马骨干波动、神马机房被攻击、神马开发误操作删库了)实在是苦的一逼,看惯了高大上的技术,今天我们转换下眼球,唠一唠基层大众农民工曾经苦涩的那些年—运维前一代的些许无奈及改进优化之路。
相信各位盆友在搬砖的过程中,肯定也遇到让你很蓝瘦香菇而又无能为力的事吧,比如咱们即将要阐述的主题,曾经一度让小学毕业的俺很受伤,也很懵逼,甚至痛苦到怀疑人生。下面我们正经的来瞅瞅,到底是啥玩意这么犀利。
2.1.1 DDos攻击
ddos攻击是最让人头痛的问题,大流量的DDOS攻击,会导致机房出口被堵,严重影响游戏业务正常访问,下面是被撸的一些情形:





在两三年前,针对ddos攻击,我们只能依靠机房本身的综合实力,除此之外,没有其它好的办法,只有干瞪眼的份,好一点的机房会有一些措施,如:
- 机房本身的硬件防火墙,可以清洗一定规模的异常流量;
- 针对被经常攻击的项目,迁移至高防区域,通过一定的策略进行防护。
而现在,如果攻击者攻击的是自有项目服务器,咱们可以通过以下的方式进行尝试防护
- 更改游戏架构,把前端入口统一单独出来,然后将统一入口架到含有攻防平台的cdn厂商,利用cdn的特征隐藏
- 掉前端统一入口ip,同时前端在连接后端时进行加密处理,从而隐藏后端ip。
通过中转,利用商业的防护平台第三方云盾,把异常流量进行清洗,如阿里云盾等。
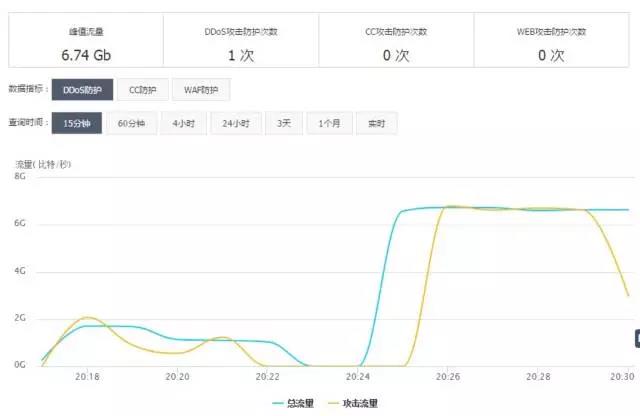
当然,还有其它的方式,比如之前公众号提到的,安装轻量型DDos防护工具-Dshield,可能也可以起到一定的作用,但如果攻击流量规模达几十G,还是得架构、CDN分流、第三方云盾来着手。
2.2.1 更新/合服断线问题
更新合服操作方式老套,很low的在机器上面跑ssh并发脚本进行更新维护,若出现网络抖动,则更新合服操作等都会因此而中断,特别是如果刚好是进行数据库的处理时,那就比较尴尬了,将需要重新恢复数据然后再进行处理。
优化改进
使用salt替代原始的上机器跑并发脚本的方式,防止网络中断所引起的更新问题,当因网络抖动而重新连接机器时,可使用salt-run jobs 来查看任务执行情况,如:
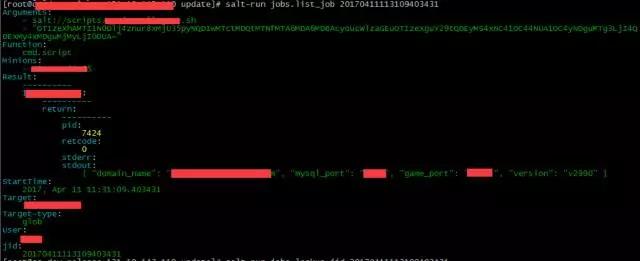

当然salt博大精深,这边介绍的只是其中的一个点,想进一步了解的盆友,可参加官网或者本公众号文章“saltstack的取经之路”,反正俺的感觉是自从用上了salt,发现腰不酸了,腿不疼了,搬砖也更有劲了,心情瞬间舒畅了许多,幸福感飙升呀,salt你值得拥有的。
2.2.2 批量装服
经历过页游时代的小伙伴应该有同感,当页游开服量逐渐增大时,会给运维效率带来了极大的挑战,传统的一个一个服部署的方式已经不能满足日常的运维要求,如下面此款游戏的日开服量达到70+,按传统的方式部署的话,莫非这是要通宵部署的节奏,什么,要通宵?感觉整个人都不好了,反正咱内心是拒绝的。
优化改进
为满足日益严峻的运维需求,我们优化了部署方式,总体思路为:通过采集数据,达到自动推荐服务器群集的功能,从而实现批量部署。
自动推荐群组的两个基本阀值是群组字段中的“最低内存”和“最低CPU”
自动推荐群组的功能:蓝海后台系统每天凌晨零点到客户端进行一次服务器性能数据采集,而客户端数据采集核心参考如下:



通过上面信息采集与分析,从而实现如下图样的批量部署界面图,部署完几十上百个区服也只是分分钟的事,动动鼠标就可以,So easy 。
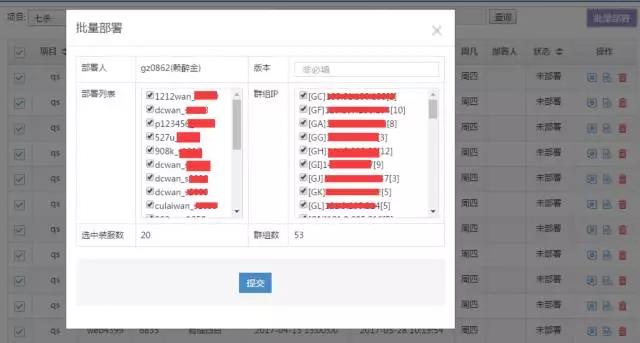
2.2.3 域名重新解析
页游开服量逐渐增大,带来的必然是合服量也日常增大,如下图某游戏的日合服量将近80,如果是用A记录解析的域名,则在合服时将面临着大量域名重新解析的问题
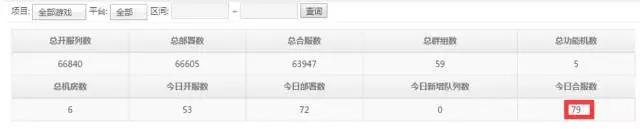
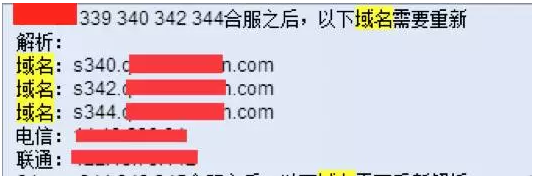
手动的人工解析,二十只手脚指一起忙活,估计也是累的够呛,可能还不能满足需求,咱们可是集网络、系统 、开发于一身的高质量高学历的“复合性人才”,怎么可以做这么low的事呢,那必须不行啊,这是不符合身份的
优化改进
开发自动化域名解析后台,实现海量域名自动化自助化的批量解析
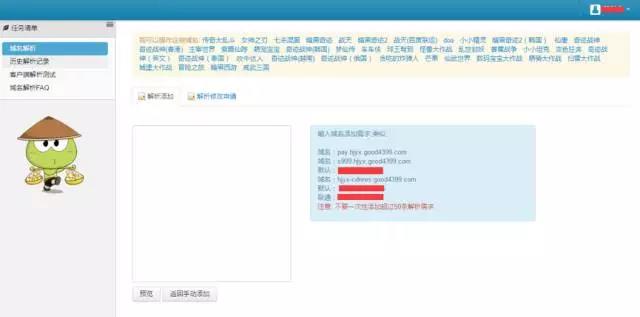

除此之外,也可通过整改游戏架构的方式,统一前端入口,把所有前端集合在一台或者多台机器上面,当区服被合服时,源服的前端直接软链到目标服,从而实现访问源机会自动连接目标服的结果,规避掉重新解析域名,如下图:
当然还可以以cname 的方式解析,但cname方式同样是需要重新解析一遍,并且随着合服次数的增多,某目标服存在多次合服的可能,这样cname重数多了,可能会引起问题,不确定哟。
2.3.1 BGP转发
游戏玩家分布全国各地,而国内网络错综复杂,会存在因为种种网络问题导致部分玩家连不上游戏gateway的端口,像一些小运营商网络的玩家,因为本身网络运营商的原因,我们会不可控,眼睁睁的看着玩家流失。再加上时不时的南北骨干网络抽风一下,站在技术小白玩家的角度来说,会造成极差的体验,最后就是玩家会说:“怪我咯?肯定都是你们的错了。”

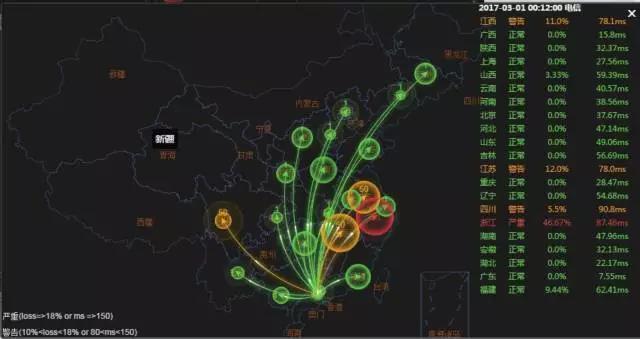
优化改进
选用优质网络的BGP机房部署中转服务器,结合客户端的逻辑判断处理,如果玩家连接不上游戏服gateway的端口则尝试通过中转机器进行重连,以增大游戏联通率。通过我们最新的定制策略,大概可以挽回10%左右用户的游戏体验。

2.3.2 APM实时地域性监控报警
以前没有APM时,当玩家登录异常报障,往往需要玩家配合帮忙收集信息才能定位问题,特别是手游时代更是繁琐,例如需要安装DNS&Ping软件啥的,加上大世界手游产品模块架构本身就相对复杂,玩家到游戏的整个逻辑交互过程不透明,若是发生区域性网络问题,那就更坑爹了,巨耗时间不说,吃力也不讨好呀。
优化改进
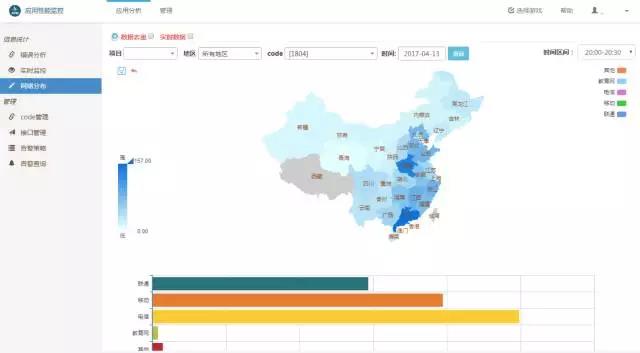
开发APM性能监控后台,把玩家连接游戏的整个逻辑交互过程数据化、透视化。
具体的思路为:跟手游客户端研发协商,把游戏内部的逻辑交互埋点打日志,通过接口统一上报至APM后台,APM后台主要做web可视化呈现。这样既能准确、有效地定位异常问题,也能为研发、运维、运营提供优化指标。


上述问题及优化来源于我们的“错题本”的归纳与总结,都是曾经的血泪史,若对你产生点点作用,请不吝点赞打赏,哈哈,最后 我们走的可能不快,但我们一直在进步,just do it,肯定有一份收获属于你。干了这碗毒鸡汤,继续搬砖了,哎妈,骨干又抽了……
原文来自微信公众号:运维军团
原文来自:http://www.yunweipai.com/archives/13430.html
本文地址:https://www.linuxprobe.com/webgame-devops-things.html编辑员:华世发,审核员:逄增宝
本文原创地址:https://www.linuxprobe.com/webgame-devops-things.html编辑:public,审核员:暂无







