

| 导读 | 临近月底,用户量上来,发现业务进程频繁从Eureka上掉下来,观察后发现掉下来前进程CPU一直占用比较高。排查得知服务器的Java进程CPU占用高导致的网页请求超时。随后进行了如下排查修复。 |
一个管理平台门户网页进统计页面提示请求超时,随进服务器操作系统检查load average超过4负载很大,PID为7163的进程占用到了800%多。
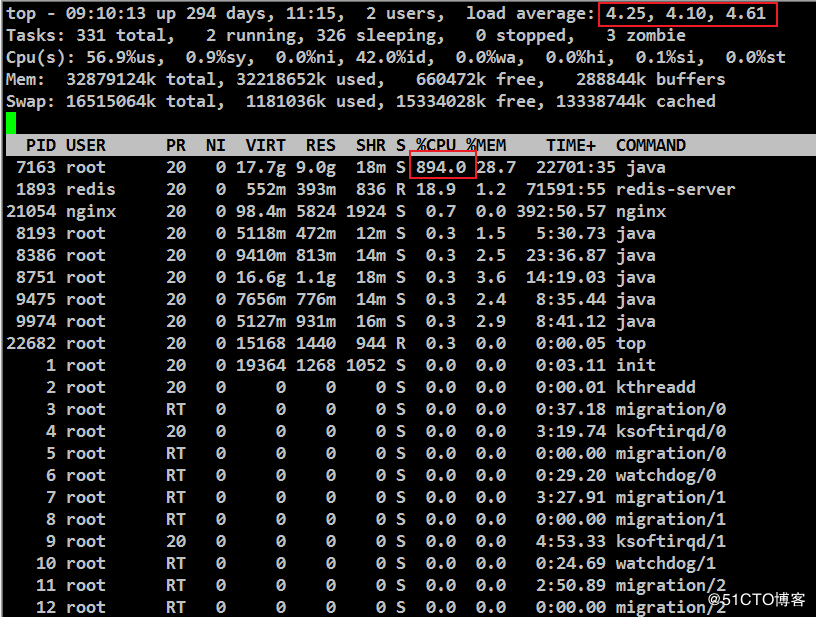
根据这种故障的一般处理思路,先找出问题进程内CPU占用率高的线程,再通过线程栈信息找出该线程当时在运行的问题代码段,操作如下:
2.1、根据思路查看高占用的“进程中”占用高的“线程”,追踪发现7163的进程中16298的线程占用较高,使用命令:
top -Hbp 7163 | awk '/java/ && $9>50'
显示结果:
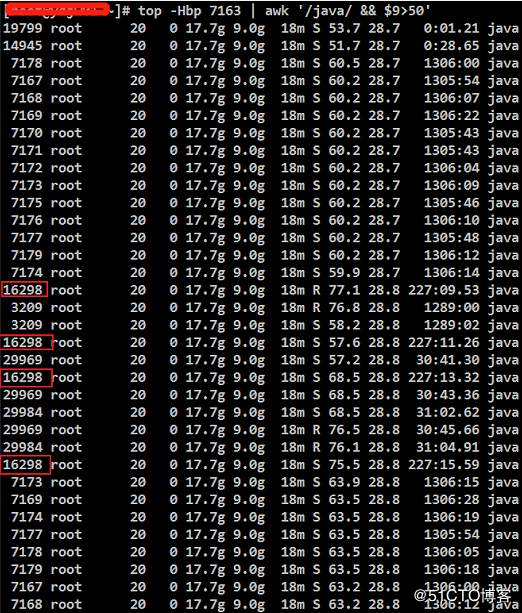
2.2、将16298的线程ID转换为16进制的线程ID。
printf "%x\n" 16298 3faa
2.3、通过jvm的jstack查看进程信息,发现是调用数据库的问题。
jstack 7163 | grep "3faa" -A 30
显示结果:
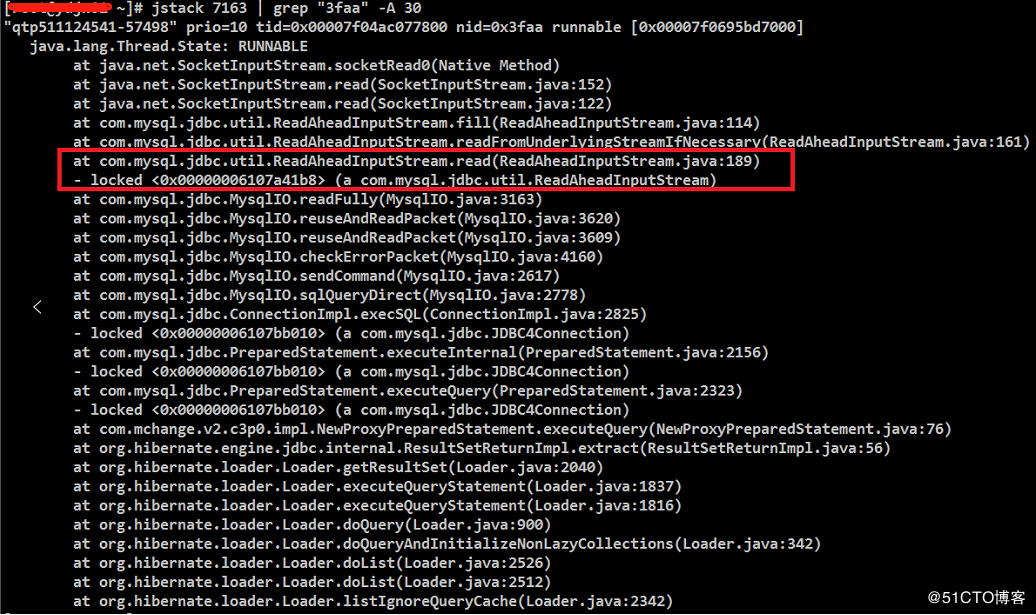
2.4、既然是数据库的问题就检查数据库,思路是先打印了所有在跑的数据库线程,检查后发现跟进情况找到问题表:
2.4.1、打印mysql现有进程信息,并把信息生成log文件,使用的命令如下:
mysql -uroot -p -e "show full processlist" > mysql_full_process.log
2.4.2、过滤log文件,发现查询最多的表,使用的命令如下:
grep Query mysql_full_process.log
2.4.3、确认表中数据量,发现表中已经有将近300万条数据,判断问题是查询时间过长导致的,使用的命令如下:
use databases_name; select count(1) from table_name;
2.4.4、确认表是否有索引,发现表未创建索引;
show create table table_name\G
询问了研发表的数据是否重要,确认不重要,检查字段有时间字段,根据时间确认只留一个月的数据,操作如下:
3.1、清理数据只保留一个月的数据,清理后数据只剩下4000多,使用命令如下;
delete from table_name where xxxx_time < '2019-07-01 00:00:00' or xxxx_time is null;
3.2、由于表未加索引,所以给表创建索引,使用命令如下:
alter table table_name add index (device_uuid);
3.3、检查索引是否创建,已经有device_uuid的索引。
show create table table_name;
处理后进程的CPU占用到了40%,本次排查主要用到了jvm进程查看及dump进程详细信息的操作,确认是由数据库问题导致的原因,并对数据库进行了清理并创建了索引。
在处理问题后,又查询了一下数据库相关问题的优化,有方案说在mysql配置文件中添加innodb_buffer_pool_size参数也可以优化查询查询时间,但该参数的意义把数据放到内存了,也就是说如果数据更新了,还会导致buffer失效,通常的优化方法还是添加索引。该方法添加参数具体如下:
innodb_buffer_pool_size=4G
原文来自:https://blog.51cto.com/rongshu/2426712
本文地址:https://www.linuxprobe.com/cpu-overshoot-troubleshooting.html编辑:KSJXAXOAS,审核员:逄增宝
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/






