

| 导读 | 如果你有心学习数据科学,那么你一定会在脑海中想过下面的问题:没有或者只有很少的数学知识,我能做一个数据科学家吗?数据科学必需的数学工具有哪些? |
如果你有心学习数据科学,那么你一定会在脑海中想过下面的问题:
没有或者只有很少的数学知识,我能做一个数据科学家吗?
数据科学必需的数学工具有哪些?
有很多优秀的包可用于建立预测模型或者数据可视化。其中最常用的用于描述和预测分析的一些包有:
- Ggplot2
- Matplotlib
- Seaborn
- Scikit-learn
- Caret
- TensorFlow
- PyTorch
- Keras
多亏了这些包,任何人都可以建立起一个模型或者实现数据可视化。然而, 坚实的数学基础对于修改你的模型让你的模型性能更好更加可靠来说是十分必要的。建立模型是一回事,解释模型得出可用于数据驱动的决策的有意义的结论又是另一回事。用这些包之前,理解每个包中的数学原理是很重要的。因为这样你才不是简单地只是把这些包作为一个黑盒来使用。
假设我们要建立一个多重回归模型。在此之前,我们需要问一下自己下面的这些问题:
- 我的数据集有多大?
- 我的特征变量和目标变量是什么?
- 什么预测特征与目标变量关联性最大?
- 什么特征是重要的?
- 我需要量化特征值吗?
- 我的数据集应该如何分成训练集和测试集?
- 什么是主成分分析(PCA)
- 我应该用PCA移除多余特征吗?
- 我要如何评估我的模型?用R2,MSE还是MAE?
- 我应该如何提升模型预测的能力?
- 我应该使用正则化的回归模型吗?
- 什么是回归系数?
- 什么是截距?
我应该使用诸如K近邻回归或者支持向量回归这种非参数回归模型吗?
我的模型中有哪些超参数,如何对其进行微调以获得性能最佳的模型?
没有良好的数学背景,你就无法解决上面提到的问题。 最重要的是,在数据科学和机器学习中,数学技能与编程技能同等重要。 因此,作为有志于数据科学的人,你必须花时间研究数据科学和机器学习的理论和数学基础。 你构建可应用于实际问题的可靠而有效的模型的能力取决于您的数学基础。
现在我们来聊聊数据科学还有机器学习所必需的一些数学工具。
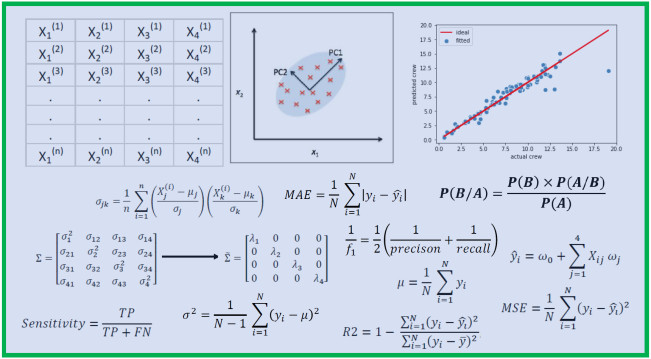
统计与概率学可用于特征的可视化,数据预处理,特征转换,数据插入,降维,特征工程,模型评估等。
这里是你需要熟悉的概念:均值,中位数,众数,标准差/方差, 相关系数和协方差矩阵,概率分布(二项,泊松,正太), p-值, 贝叶斯理论(精确性,召回率,阳性预测值,阴性预测值,混淆矩阵,ROC曲线), 中心极限定理, R_2值, 均方误差(MSE),A/B测试,蒙特卡洛模拟。
大多数机器学习模型都是由带有许多特征或者预测因子的数据集建立的。因此,熟悉多元微积分对于建立机器学习模型及其重要。
这里是你需要熟悉的概念:多元函数;导数和梯度; 阶跃函数,Sigmoid函数, Logit函数, ReLU(整流线性单元)函数;损失函数;函数作图;函数最大最小值。
线性代数是机器学习中最重要的数学工具。 数据集通常都表示为矩阵。 线性代数常用于数据预处理,数据转换,降维和模型评估。
这里是你需要熟悉的概念:向量;向量的范数;矩阵;矩阵转置;矩阵的逆;矩阵的行列式;矩阵的迹;点积;特征值;特征向量
大多数机器学习算法通过最小化目标函数来建立预测模型,由此学习应用于测试数据的权重以获得预测的标签。
这里是你需要熟悉的概念:损失函数/目标函数;似然函数;误差函数;梯度下降算法及其衍生(如随机梯度下降)
总之,我们已经讨论了数据科学和机器学习所需的基本数学和理论技能。 有几门免费的在线课程可以教你数据科学和机器学习所必需的数学知识。 作为有志于数据科学的人,请记住,数据科学的理论基础对于构建高效且可靠的模型至关重要。 因此,您应该投入足够的时间来研究每种机器学习算法背后的数学理论。
原文来自:https://bigdata.51cto.com/art/202101/639293.htm
本文地址:https://www.linuxprobe.com/data-science-field.html编辑:清蒸github,审核员:逄增宝
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/






