| 导读 | Java基于JVM运行的特性使得Java程序可以一次编写,多处运行,摆脱分布式集群中不同操作系统和硬件处理框架带来的束缚,使得开发者可以更加专注于代码逻辑的开发。 |
近年以来,大数据应用取得了长足的进展,各种大数据处理框架也应运而生,并得到了业界的高度认可,如Hadoop生态、Spark系列、Flink、Cassandra、Hive等等。这类编程模型通常采用分治的思想,将大的数据处理作业拆分为多个小的计算任务,分配到分布式集群中的不同节点中运行,然后将结果汇聚起来,得出最终结果。
由于使用习惯等关系,业内主流的大数据处理框架都采用Java语言进行编写。原因在于以下几点:
1、很多程序开发人员对于Java语言比较熟悉,使用起来轻车熟路;
2、Java提供了便捷的自动内存管理机制,避免了用户在处理内存过程中可能出现的问题;
3、Java基于JVM运行的特性使得Java程序可以一次编写,多处运行,摆脱分布式集群中不同操作系统和硬件处理框架带来的束缚,使得开发者可以更加专注于代码逻辑的开发;
4、Java语言拥有成熟的社区和丰富的编程资源,可以实现快速开发,出现问题也可以快速寻求帮助。

正是基于这些优点,Java语言成为了目前最主流大数据编程技术。但是,在实际使用的过程中,开发者们发现了一系列JVM相关的性能瓶颈,主要包括以下几个方面:
1、垃圾回收(GC)占用时间长,在一些大数据应用中,GC时间甚至可以达到总执行时间的50%;
2、GC频率高,造成任务执行频繁暂停,应用吞吐率降低,响应延迟升高;
3、GC算法挤占应用线程CPU资源,存在GC线程竞争时,大数据应用执行时间增长可达60%;
4、数据对象在分布式节点间传输时需要序列化和反序列化,在某些大数据应用中,用时占比可达30%;
5、JVM冷启动时需要大量的类加载和代码即时编译工作,在应用执行中的用时可达数十秒;
6、JVM运行和维护需要内存消耗,在内存紧张的情况下,可能因为内存耗尽或内存碎片触发OOM错误。
总的来说,这些问题的产生,可以归纳为以下一些原因:
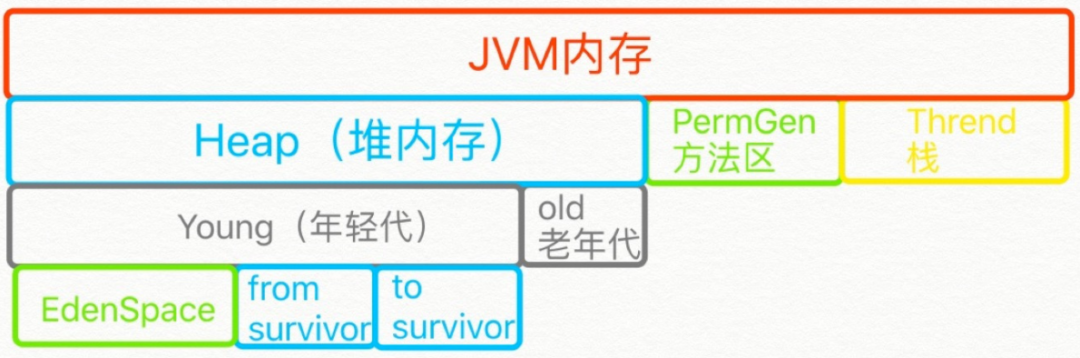
与普通的Java应用不同,大数据应用是“内存密集”型的,应用的内存使用量更大,在大数据处理框架下,JVM的内存使用压力具体来源于:
(1)大数据应用数据计算和存储产生的大量内存消耗,大量数据在计算过程中需要同时被读取到内存中,而一些应用为了更进一步加快处理速度,将中间数据的聚合和可重用数据也缓存在内存当中,这决定了JVM在执行大数据应用时将面对更大的内存使用量;
(2)数据在JVM堆内存当中以对象的形式存储需要额外的内存占用,对象在JVM当中的数据结构包含了对象头以及对其它对象的引用,而数据本身在对象中的空间占比往往不超过一半。这些对象的外壳伴随着数据缓存在内存当中,也需要占用相当数量的空间;
由于JVM垃圾回收机制的原因,会经常触发全局暂停,而这个问题很难通过简单的增减内存大小来解决,如果降低内存大小,GC的触发频率会增加,对象被扫描和的去的次数增加,应用程序的吞吐量相应降低。可用内存不足还会影响到应用的正常缓存和处理机制,甚至引发内存溢出。而如果提升内存大小,单次GC则需要处理更多的数据对象,平均的暂停时间加长,应用程序的最大延迟相应增加。对于周期性标记扫描的GC算法而言,还会在最终触发GC之前消耗更多CPU时序进行不必要的标记。
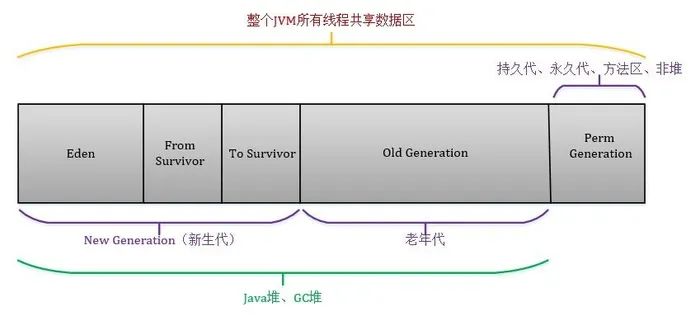
大数据应用中数据在内存当中保留的时间周期与普通应用不尽相同。在传统应用中,堆内存中创建的绝大部分对象在产生之后不久就不再被使用,经典的GC算法正是基于这种内存使用模式,将堆内存进行粗粒度的年代划分,绝大部分瞬时对象会在针对年轻代的Minor GC当中很快被清理。而大数据应用产生的对象有两种,一种是由控制大数据处理框架运行逻辑的代码产生的,即控制路径对象,它们的内存使用模式一般依旧符合弱世代假设。另一种是输入数据和计算中间数据在大数据处理框架中封装生产的,统称为数据路径对象。这种对象的内存使用模式要更加复杂,它们可能在内存中长时间累积或缓存,也可能在一个迭代轮次后被清理和输出。通常来说,数据路径所创建的对象数量远超控制路径。传统GC算法并不能适应大数据环境下内存使用模式的这种变化,原因在于:
(1)当前GC算法下,长时间存活的数据路径对象最终都会晋升到老年代中,它们在数次Minor GC当中幸存并最终晋升的过程中,需要在内存中多次移动。而对象移动是GC循环当中最耗时的部分,每一次移动都意味着内存读写,而内存位置的改变也需要对相关引用的指针进行更新。考虑到数据路径对象的数量极为庞大,整个晋升过程会消耗大量CPU时间,触发多次GC暂停;
(2)数据路径对象在晋升到老年代之后,在作业执行的时间尺度上,短时间内也不会被回收。传统的GC算法不会考虑这些对象的存活时间,在涉及到老年代空间的MajorGC或者Mixed GC之前还是会整个堆内存空间进行标记扫描,这些标记扫描过程对于长时间存活的数据对象来说是不必要的。当长时间存活对象占用老年代的比例过高,每次传出较大代价的Major GC就只能回收有限大小的空间,可能造成GC频繁触发,部分缓存数据被迫转移到磁盘,甚至出现OOM错误,浪费大量的CPU时间和全局暂停时间,影响到应用执行效率。
大数据处理框架将计算任务分配到各个执行器JVM节点之后,并不会干预JVM的具体执行过程,每个执行器JVM独立运行,并不感知分布式集群中其它执行器JVM的执行情况,作业的整体进度,以及集群和节点的内存资源使用情况,只是根据自身的运行状态作出触发GC,调整堆内存,进行代码即时编译等决策,而这些决策从历史和全局的角度上观察可能并不是最优的。原因在于:
(1)JVM不清楚任务执行产生的数据对象特征,例如对象数量、内存占用大小、生命周期等,只能根据弱世代假说,对所有对象进行统一的管理。由于大数据应用产生的大量对象长时间存活,JVM的内存管理效率会受到严重影响,而这些对象本可以通过大数据框架对用户代码和数据流的全局静态分析进行甄别。
(2)大数据处理框架并不考虑JVM具体的内存管理机制,将所有JVM节点的内存当做连续的全局地址空间,但是实际上JVM在GC算法下对堆内存采取分代管理,存在非连续区域,对象在内存中离散分布,另外大数据处理框架在采用全局地址空间的物理架构下,可能产生大量跨节点对对象引用,给JVM的GC任务带来了远程内存访问的负担。
(3)大数据处理框架下的JVM之间不清楚彼此的运行情况,如果大数据操作需要在各个JVM之间同步,由于JVM独立进行GC决策,大数据操作的执行就可能被不同的JVM的GC连续打断,另外由于互相不感知,处于同一物理节点的JVM之间可能内存资源分配不合理,而大数据框架在相关问题上缺少统筹协调。
因此,开发者们需要针对这些问题产生的原因,进行针对性优化。我们下次文章将会继续讨论这个问题。
原文来自:https://www.51cto.com/article/745094.html
本文地址:https://www.linuxprobe.com/java-virtual-machine-optimization.html编辑:KSJXAXOAS,审核员:逄增宝
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/