| 导读 | CPU是操作系统稳定运行的根本,CPU的速度与性能在很大程度上决定了系统整体的性能,因此,CPU数量越多、主频越高,服务器性能也就相对越好。 |
一般互联网的项目都是部署在linux服务器上的,如果linux服务器出了问题,那么咱们平时学习的高并发,稳定性之类的是没有任何意义的,所以对linux性能的把握就显得非常重要,当然很多同学可能觉得这些是运维同学的事情,但是我不这么认为,不管你是架构师,还是crud boy,对项目有个全局的掌控是一项非常重要的基本素质,所以总结了这篇文章,希望对您有用,如果您觉得我写的还不错,看完记得点个赞,点个再看哦。咱们废话不用多说,直接进入正题。
CPU是操作系统稳定运行的根本,CPU的速度与性能在很大程度上决定了系统整体的性能,因此,CPU数量越多、主频越高,服务器性能也就相对越好。
内存的大小也是影响Linux性能的一个重要的因素,内存太小,系统进程将被阻塞,应用也将变得缓慢,甚至失去响应;内存太大,导致资源浪费。
磁盘的I/O性能直接影响应用程序的性能,在一个有频繁读写的应用中,如果磁盘I/O性能得不到满足,就会导致应用停滞。好在现今的磁盘都采用了很多方法来提高I/O性能,比如常见的磁盘RAID技术。
Linux下的各种应用,一般都是基于网络的,因此网络带宽也是影响性能的一个重要因素,低速的、不稳定的网络将导致网络应用程序的访问阻塞,而稳定、高速的网络带宽,可以保证应用程序在网络上畅通无阻地运行。幸运的是,现在的网络一般都是千兆带宽或光纤网络,带宽问题对应用程序性能造成的影响也在逐步降低。
![]()
这里需要注意的是:load average这个输出值,这三个值的大小一般不能大于系统CPU的个数
查看系统cpu的信息
cat /proc/cpuinfo中的信息
其中cpu cores即为cpu的核数
也可以用cat /proc/cpuinfo |grep "cores"|uniq直接查看
cat /proc/cpuinfo |grep "cores"|uniq cpu cores : 2
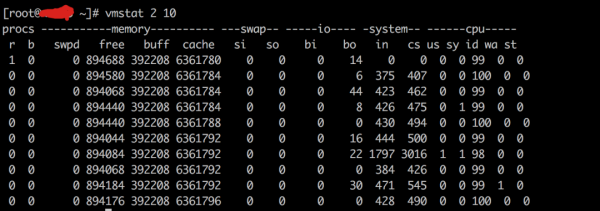
r表示运行和等待cpu时间片的进程数,这个值如果长期大于cpu的个数,则需要增加系统cpu
b表示等待资源的进程数
us列显示了用户进程消耗CPU时间百分比,us比较高的时候,说明用户进程消耗cpu的时间多,如果长期大于50%,就需要优化程序和算法
sy列显示了内核进程消耗的cpu时间百分比,sy值较高的时候,说明内核消耗的cpu资源很多
根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。
sar命令会增加系统开销 但是影响不大
安装sar命令:
yum install sysstat
u显示系统所有cpu在采样时间内的负载状态)图片%user:用户进程消耗cpu的时间百分比:
sar -u 3 5
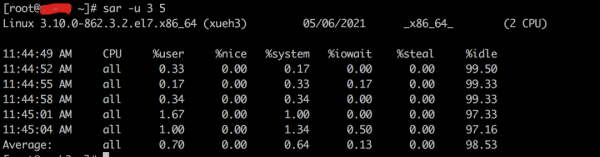
%nice:运行正常进程所消耗cpu的百分比
%system:系统消耗cpu时间百分比
%iowait:IO等待所占用cpu时间百分比
%steal:内存在相对紧张的环境下pagein强制对不同页面进行的steal操作
%idle:cpu处在空闲时间的百分比
free -m
查看以M为单位的内存使用情况

一般有这样一个经验公式:
应用程序可用内存/系统物理内存>70%时,表示系统内存资源非常充足,不影响系统性能。
应用程序可用内存/系统物理内存<20%时,表示系统内存资源紧缺,需要增加系统内存。
20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
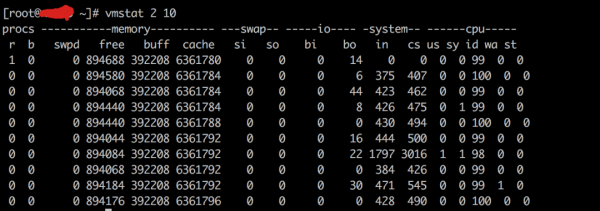
swpd表示切换到内存交换去的内存数量(k),如果swpd的值不为0,或者比较大,但是si,so的值长期为0,这种情况不用担心,不会影响性能
free表示空闲的物理内存数量
buffer表示buffers cache的内存数量,一般对设备的读写才需要缓冲
cache表示page cached的内存数量。一般作为文件系统cached,频繁访问的文件都会被cached,如果cache值较大,说明cached的文件较多,如果此时IO中的bi比较小,说明文件系统效率比较好
si表示由磁盘调入内存,也就是内存进入内存交换区的数量
so表示由内存调入磁盘,也就是内存交换区进入内存的数量 一般情况下,so si的值都为0。如果si so的值长期不为0,则表示系统内存不足,需要增加内存
iostat -d 2 10
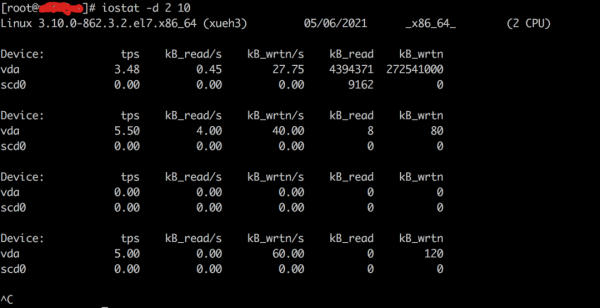
Blk_reads/s 每秒读取的数据块数
Blk_wrtn/s 每秒写入的数据块数
Blk_read 读取的所有块数
Blk_wrtn 写入的所有块数
这几个值没有标准 如果长期都很大 肯定是不正常的
sar -d 2 5
await 平均每次设备I/O操作的等待时间(毫秒)
svctm 平均每次设备I/O操作的服务时间(毫秒)
%util 一秒中有百分之几的时间用于I/O操作
正常情况下svctm应该是小于await的,svctm的值和磁盘性能,cpu内存等都有关系
如果svctm的值和await的值相近表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm,表示I/O队列等待时间太长,系统上的应用程序将变慢,此时可以通过更换更快的硬盘来解决问题
%util越小越好,如果%util接近100%表示磁盘产生的I/O请求太多,I/O系统已经满负载在工作,此时可以通过优化程序或者更换更快的磁盘来解决问题
网络性能评估
通过ping命令检测网络的连通性。
通过netstat -i 组合检测网络接口状况。
通过netstat -r 组合检测系统路由表信息。
通过sar -n 组合显示系统的网络运行状态(sar -n DEV 5 3)。
常用分析:
查看tcp连接数最多的ip:
sudo netstat -pant | grep ":22" | awk '{print $5}' | awk -F":" '{print $4}' |sort|uniq -c|sort -nr
解释:
awk -F":" '{print $4}' 表示把结果的第4列用:号分割
sort -nr 排序,-n以数值大小排序,-r倒序,从大到小。
uniq -c 删除重复的行,-c表示加上每行出现的次数。
netstat命令是一个监控TCP/IP网络的非常有用的工具, 它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。
netstat -pant
参数-p :显示正在使用Socket的程序识别码和程序名称;
参数-a :显示所有连线中的Socket;
参数-n :直接使用ip地址,而不通过域名服务器;
参数-t :显示TCP传输协议的连线状况。
提取访问nginx服务器最多的10个ip。
cat access.log | awk '{print $1}' | sort | uniq -c | sort -nr | head -n10
原文来自:https://os.51cto.com/art/202105/661070.htm
本文地址:https://www.linuxprobe.com/linux-commands-cpu.html编辑:roc_guo,审核员:逄增宝
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/