那么,什么是索引呢?
索引(Index)是帮助MySQL高效获取数据的数据结构。可以得到索引的本质:索引是数据结构。
可以理解为“排好序的快速查找数据结构”,比如查找树~
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
类似大学图书馆建书目索引,提高数据检索效率,降低数据库的IO成本。
通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占空间的。
虽然索引大大提高了查询速度,同时确会降低更新表的速度,如对表进行INSERT、UPDATE、DELETE。
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段。
都会调整因为更新所带来的键值变化后的索引信息。
单值(列)索引:即一个索引只包含单个列,一个表可以有多个单列索引。
唯一索引:索引列的值必须唯一,但允许有空值。 -> 主键是特殊的唯一索引,因为其不允许有空值。
复合(组合)索引:即一个索引包含多个列。
全文索引:FULLTEXTl类型索引,可以在CHAR,VARCHAR,或者TEXT类型的列上创建,仅MyISAM支持。
空间索引:对空间数据库的支持,GIS系统什么的。。。。哎呀,不看这里了,看起来比较吊。
各存储引擎支持的索引结构如下表(摘自MariaDB的KB):
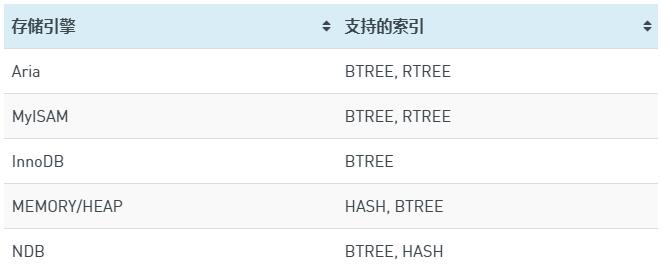
其中BTREE是默认的索引结构,而对于MEMORY存储引擎,HASH则是默认的。
B-TREE:支持 >, >=, =, >=, < 、BETWEEN以及LIKE一个常量,比如"MariaDB%"可以支持B-Tree索引,而"%Maria"则不支持。 Hash:仅支持 =或<=>操作符,
R-tree:空间索引上的数据结构,不看了.....太难。
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其他表关联的字段,外键关系建立索引
- 频繁更新的字段不适合建立索引,因为每次更新不单单是更新了记录还会更新索引
- WHERE条件里用不到的字段不创建索引
- 单键/组合索引的选择问题,who?(在高并发下倾向创建组合索引)
- 查询中排序的字段,排序的字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
- 表记录太少
- 经常增删改的表
提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE、和DELETE。
因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排序的数据建立索引。
注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。
这里找到一篇好文章,摘自知乎:mysql索引最左匹配原则的理解? 作者:沈杰
表结构如下:有三个字段,分别是id,name,cid
CREATE TABLE `student` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `cid` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `name_cid_INX` (`name`,`cid`), ) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
索引方面:id是主键,(name,cid)是一个多列索引。
下面是你有疑问的两个查询:
EXPLAIN SELECT * FROM student WHERE cid=1;
![]()
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
![]()
你的疑问是:sql查询用到索引的条件是必须要遵守最左前缀原则,为什么上面两个查询还能用到索引?
讲上面问题之前,我先补充一些知识,因为我觉得你对索引理解是狭隘的:
上述你的两个查询的explain结果中显示用到索引的情况类型是不一样的。,可观察explain结果中的type字段。
你的查询中分别是:
1. type: index
2. type: ref
解释:
index:这种类型表示是mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个复合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。
所以:对于你的第一条语句:
EXPLAIN SELECT * FROM student WHERE cid=1;
判断条件是cid=1,而cid是(name,cid)复合索引的一部分,没有问题,可以进行index类型的索引扫描方式。explain显示结果使用到了索引,是index类型的方式。
ref:这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一 一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。
有些了解的人可能会问,索引不都是一个有序排列的数据结构么。不过答案说的还不够完善,那只是针对单个索引,而复合索引的情况有些同学可能就不太了解了。
下面就说下复合索引:
以该表的(name,cid)复合索引为例,它内部结构简单说就是下面这样排列的:
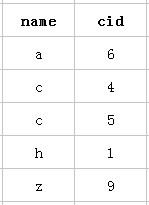
mysql创建复合索引的规则是首先会对复合索引的最左边的,也就是第一个name字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的cid字段进行排序。其实就相当于实现了类似 order by name cid这样一种排序规则。
所以:第一个name字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个cid字段进行条件判断是用不到索引的,当然,可能会出现上面的使用index类型的索引。这就是所谓的mysql为什么要强调最左前缀原则的原因。
那么什么时候才能用到呢?当然是cid字段的索引数据也是有序的情况下才能使用咯,什么时候才是有序的呢?观察可知,当然是在name字段是等值匹配的情况下,cid才是有序的。发现没有,观察两个name名字为 c 的cid字段是不是有序的呢。从上往下分别是4 5。
这也就是mysql索引规则中要求复合索引要想使用第二个索引,必须先使用第一个索引的原因。(而且第一个索引必须是等值匹配)。
所以对于你的这条sql查询:
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
没有错,而且复合索引中的两个索引字段都能很好的利用到了!因为语句中最左面的name字段进行了等值匹配,所以cid是有序的,也可以利用到索引了。
你可能会问:我建的索引是(name,cid)。而我查询的语句是cid=1 AND name='小红'; 我是先查询cid,再查询name的,不是先从最左面查的呀?
好吧,我再解释一下这个问题:首先可以肯定的是把条件判断反过来变成这样 name='小红' and cid=1; 最后所查询的结果是一样的。那么问题产生了?既然结果是一样的,到底以何种顺序的查询方式最好呢?所以,而此时那就是我们的mysql查询优化器该登场了,mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。
所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,所以mysql查询优化器会最终以这种顺序进行查询执行。
赞一个~不请自转,感谢原作者沈杰,如有侵权请告知。
CREATE TABLE tbl_name(Column_def1,Column_def2,Columndef3,.....index_def);
index_def:
{INDEX|KEY} [index_name] [index_type] (index_col_name,...) [index_option] ...
| {FULLTEXT|SPATIAL} [INDEX|KEY] [index_name] (index_col_name,...) [index_option] ...
| [CONSTRAINT [symbol]] PRIMARY KEY [index_type] (index_col_name,...) [index_option] ...
| [CONSTRAINT [symbol]] UNIQUE [INDEX|KEY] [index_name] [index_type] (index_col_name,...) [index_option] ...
| [CONSTRAINT [symbol]] FOREIGN KEY [index_name] (index_col_name,...) reference_definition
例子,创建一张表,三个字段:id,name,gid 为name创建索引:
MariaDB [mydb]> CREATE TABLE test(
-> id int(10) PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(10) NOT NULL,
-> gid int(3),
-> INDEX name_idx (name(5))
-> );
其中需要说明的是,name(5)就是为name列创建索引,且仅取前5个字符进行索引。
更多创建表时的SQL语法可参考:https://mariadb.com/kb/en/library/create-table/#indexes
CREATE INDEX语法如下:
CREATE [OR REPLACE] [ONLINE|OFFLINE] [UNIQUE|FULLTEXT|SPATIAL] INDEX
[IF NOT EXISTS] index_name
[index_type]
ON tbl_name (index_col_name,...)
[WAIT n | NOWAIT]
[index_option]
[algorithm_option | lock_option] ...
index_col_name:
col_name [(length)] [ASC | DESC]
index_type:
USING {BTREE | HASH | RTREE}
index_option:
KEY_BLOCK_SIZE [=] value
| index_type
| WITH PARSER parser_name
| COMMENT 'string'
algorithm_option:
ALGORITHM [=] {DEFAULT|INPLACE|COPY}
lock_option:
LOCK [=] {DEFAULT|NONE|SHARED|EXCLUSIVE}
先查看下上面创建的索引:
MariaDB [mydb]> SHOW INDEX FROM test\G;
*************************** 1. row *************************** //主键会创建一个索引
Table: test
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: id
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
*************************** 2. row *************************** //这个是我们自己创建的索引
Table: test
Non_unique: 1
Key_name: name_idx
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: 5
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
2 rows in set (0.00 sec)
现在,我们把之前创建的索引删掉,然后创建一个多列索引(name,gid)
DROP INDEX name_idx ON test;//删除索引 CREATE INDEX name_gid_idx ON test (name(5),gid DESC); //创建了多列索引,且name取前5,而gid则倒叙排列 CREATE OR REPLACE INDEX name_gid_idx ON test(name(5),gid); //修改了上面创建的这个索引
创建唯一约束时会自动创建唯一索引,但创建唯一索引时则不会创建唯一约束,且唯一索引能做到和唯一约束一样的效果。
原文来自:https://www.54371.net/linux/mariadb-study-index.html
本文地址:https://www.linuxprobe.com/mariadb-study-index.html编辑:清蒸github,审核员:逄增宝
本文原创地址:https://www.linuxprobe.com/mariadb-study-index.html编辑:清蒸github,审核员:暂无