

| 导读 | 很多 SQL 查询都是以 SELECT 开始的。不过,最近我跟别人解释什么是窗口函数,我在网上搜索”是否可以对窗口函数返回的结果进行过滤“这个问题,得出的结论是”窗口函数必须在 WHERE 和 GROUP BY 之后,所以不能” |
很多 SQL 查询都是以 SELECT 开始的。
不过,最近我跟别人解释什么是窗口函数,我在网上搜索”是否可以对窗口函数返回的结果进行过滤“这个问题,得出的结论是”窗口函数必须在 WHERE 和 GROUP BY 之后,所以不能”。
于是我又想到了另一个问题:SQL 查询的执行顺序是怎样的?
好像这个问题应该很好回答,毕竟自己已经写了上万个 SQL 查询了,有一些还很复杂。但事实是,我仍然很难确切地说出它的顺序是怎样的。
于是我研究了一下,发现顺序大概是这样的。SELECT 并不是先执行的,而是在第五个。
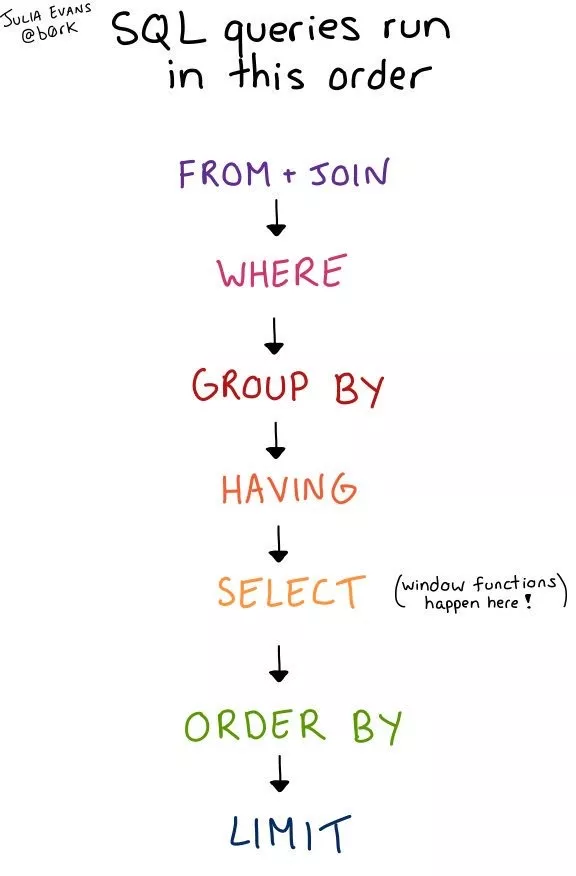
这张图与 SQL 查询的语义有关,让你知道一个查询会返回什么,并回答了以下这些问题:
- 可以在 GRROUP BY 之后使用 WHERE 吗?(不行,WHERE 是在 GROUP BY 之后!)
- 可以对窗口函数返回的结果进行过滤吗?(不行,窗口函数是 SELECT 语句里,而 SELECT 是在 WHERE 和 GROUP BY 之后)
- 可以基于 GROUP BY 里的东西进行 ORDER BY 吗?(可以,ORDER BY 基本上是在最后执行的,所以可以基于任何东西进行 ORDER BY)
- LIMIT 是在什么时候执行?(在最后!)
但数据库引擎并不一定严格按照这个顺序执行 SQL 查询,因为为了更快地执行查询,它们会做出一些优化,这些问题会在以后的文章中解释。
所以:
- 如果你想要知道一个查询语句是否合法,或者想要知道一个查询语句会返回什么,可以参考这张图;
- 在涉及查询性能或者与索引有关的东西时,这张图就不适用了。
有很多 SQL 实现允许你使用这样的语法:
SELECT CONCAT(first_name, ' ', last_name) AS full_name, count(*) FROM table GROUP BY full_name
从这个语句来看,好像 GROUP BY 是在 SELECT 之后执行的,因为它引用了 SELECT 中的一个别名。
但实际上不一定要这样,数据库引擎可以把查询重写成这样:
SELECT CONCAT(first_name, ' ', last_name) AS full_name, count(*) FROM table GROUP BY CONCAT(first_name, ' ', last_name)
这样 GROUP BY 仍然先执行。
数据库引擎还会做一系列检查,确保 SELECT 和 GROUP BY 中的东西是有效的,所以会在生成执行计划之前对查询做一次整体检查。
在实际当中,数据库不一定会按照 JOIN、WHERE、GROUP BY 的顺序来执行查询,因为它们会进行一系列优化,把执行顺序打乱,从而让查询执行得更快,只要不改变查询结果。
这个查询说明了为什么需要以不同的顺序执行查询:
SELECT * FROM owners LEFT JOIN cats ON owners.id = cats.owner WHERE cats.name = 'mr darcy'
如果只需要找出名字叫“mr darcy”的猫,那就没必要对两张表的所有数据执行左连接,在连接之前先进行过滤,这样查询会快得多,而且对于这个查询来说,先执行过滤并不会改变查询结果。

Happy girl is playing with group of books in studio
数据库引擎还会做出其他很多优化,按照不同的顺序执行查询,不过我并不是这方面的专家,所以这里就不多说了。推荐:MySQL全面优化,速度飞起来。
LINQ(C# 和 VB.NET 中的查询语法)是按照 FROM…WHERE…SELECT 的顺序来的。这里有一个 LINQ 查询例子:
var teenAgerStudent = from s in studentList
where s.Age > 12 && s.Age < 20
select s;
pandas 中的查询也基本上是这样的,不过你不一定要按照这个顺序。我通常会像下面这样写 pandas 代码:
df = thing1.join(thing2) # JOIN
df = df[df.created_at > 1000] # WHERE
df = df.groupby('something', num_yes = ('yes', 'sum')) # GROUP BY
df = df[df.num_yes > 2] # HAVING, 对 GROUP BY 结果进行过滤
df = df[['num_yes', 'something1', 'something']] # SELECT, 选择要显示的列
df.sort_values('sometthing', ascending=True)[:30] # ORDER BY 和 LIMIT
df[:30]
这样写并不是因为 pandas 规定了这些规则,而是按照JOIN/WHERE/GROUP BY/HAVING 这样的顺序来写代码会更有意义些。不过我经常会先写 WHERE 来改进性能,而且我想大多数数据库引擎也会这么做。
R 语言里的 dplyr 也允许开发人员使用不同的语法编写 SQL 查询语句,用来查询 Postgre、MySQL 和 SQLite。
本文地址:https://www.linuxprobe.com/select-sql.html编辑:J+1,审核员:逄增宝
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/







