

| 导读 | 在高性能计算、机器学习等现代应用领域中,GPU(Graphics Processing Unit)是占统治地位的计算引擎。GPU从早期的固化逻辑实现、到可编程、到今天的通用计算架构(GPGPU),其应用接口(API)随着功能和通用性的提升而变得越来越灵活和高效。 |
早期的GPU有浑名显卡也不冤枉。从软件角度来说,其逻辑架构基本上就是图形的三角形坐标变换、顶点照明、像素着色等一系列功能。因为逻辑固化、功能单纯,应用程序通过驱动接口可以直接执行这些功能,主要API就是较早版本的OpenGL和DirectX。
OpenGL源于曾经非常风光的SGI公司,然后演进成支持跨平台图形的工业标准,版本也从最初的1.x,到2.0,3.x,到今天的4.5【1】。目前Khronos Group(OpenGL标准化组织)正在推进OpenGL5.0。而DirectX是微软的windows平台上专用API。DirectX图形API最初的几个版本基本上是奋力直追OpenGL的features,直到DirectX 9.3c,微软才完成了实质上的超越。DirectX 9.3在features上大致相当于OpenGL3.3。(注意,OpenGL分为台式、嵌入式两个不同的profile,其版本之间的一一对应关系不甚明显)
随着图形算法的改进和对高质清晰画面的追求,GPU需要越来越强大的灵活性来支持纹理、材料属性、和精细度渲染,固化的逻辑显然无法跟得上这些需求。GPU实现真正意义上的可编程是支持高层渲染语言(shading language)。对应于OpenGL的高层语言是GL Shading Language(简称GLSL),对应于DirectX的高层语言是High Level Shading Language (或HLSL)。GPU的可编程流水线架构如下:
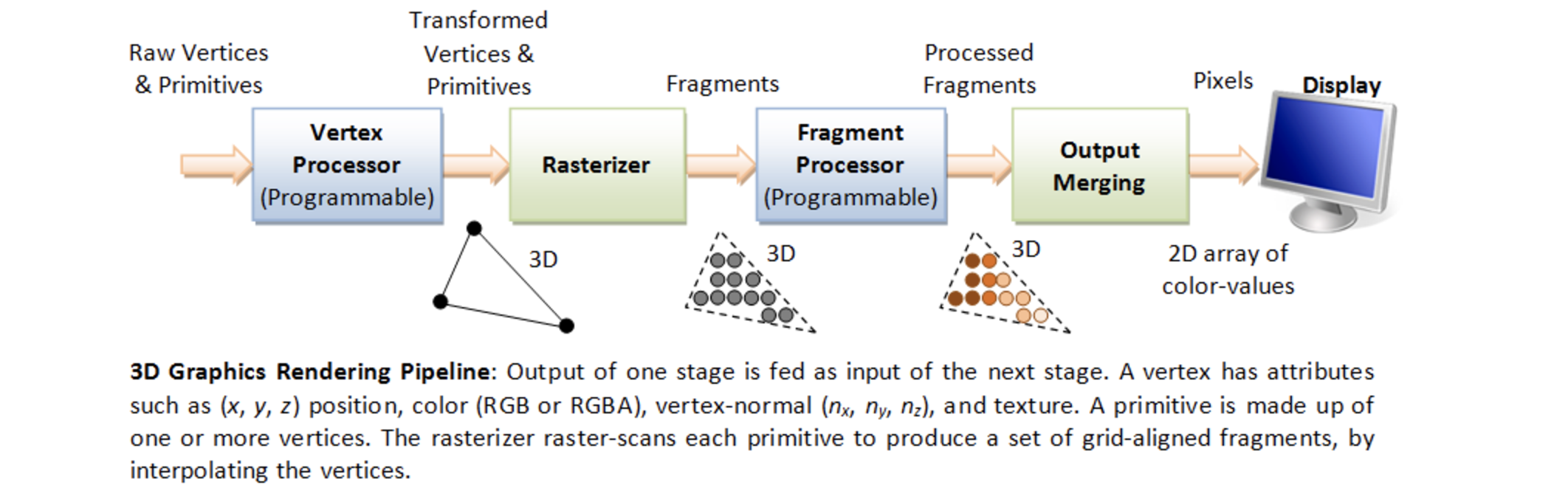
由上图可见,在GPU的逻辑流水线上,只有两个阶段是可编程的,其它的仍然是固化的硬件支持。其中,一个可编程的stage是三角形顶点处理器(vertex processor),用户可以根据自己的需求编写适当的坐标变换、光线照明等复杂程序。另一个是像素处理器(fragment processor),实现更细节的渲染和纹理映射等。两个处理器对应的GPU程序分别叫做vertex shader 和fragment shader。在DirectX中,fragment shader叫做pixel shader。
不同的GPU厂商对上述的可编程逻辑单元有不同的的硬件实现。比如,英伟达(Nvidia)早期的GeForce 系列,ARM Mali GPU都采取了离散架构,即vertex processor和fragment processor是独立的物理处理单元。英伟达直到GeForce 8 系列的Tesla微架构,才改成了归一化的GPU架构【2】,即统一的处理器可以同时执行vertex shader 和fragment shader。ARM Mali Midgard和最近的Bifrost微架构也采用了归一化的实现【3】。不过,高通(Qualcomm)的Adreno GPU一开始就是归一化的微架构。
在DirectX9.3 实现超越之后,微软在GPU API方面一直处于领跑地位。只是DirectX 10时运不济,几乎随着Windows Vista灰飞烟灭。但之后的DirectX 11改头换面,并率先推出了细分曲面(tessellation)和通用计算(compute)API,实现了从GPU 到GPGPU(general-purpose GPU)的飞跃【4】。
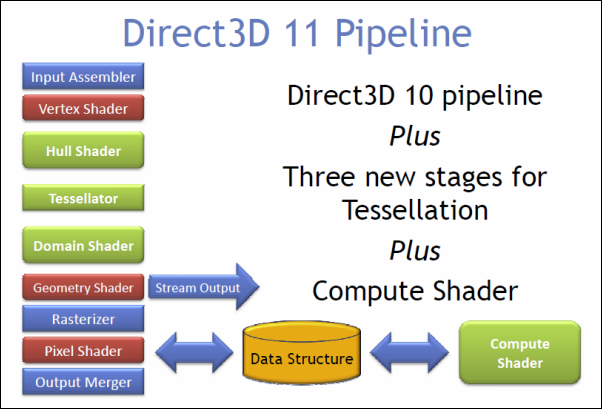
虽然从API的角度,通用计算处理器似乎是一个独立的单元,但一般的GPU物理实现都是重复利用流水线上的可编程单元(归一化的处理器),在执行通用计算GPU程序(叫做compute shader)时忽略其它的硬件功能。Vertex shader,fragment shader,和compute shader采用归一化的编程模型。
因为DirectX是微软的专用API,OpenGL社区也不甘落后,很快就推出相应的OpenGL通用计算和细分曲面功能。为了有别于DirectX,OpenGL的tessellation 程序叫做tessellation control shader和tessellation evaluation shader,分别对应于DirectX的Hull shader和Domain shader。OpenGL ES(嵌入式系统)在3.1版本引进了通用计算,但直到去年的3.2版本才正式加入tessellation功能(在此之前由Google的扩展包得以维系)。
真正跨平台的通用计算API是Khronos的OpenCL1.x 和随后的OpenCL2.x。感觉比较别扭的是,同一个Khronos Group标准化组织,却同时有两套通用计算API。简单的理解是,OpenCL是为大计算准备的(heavy-duty compute),比如在GPU上的大规模高性能科学计算。OpenGL compute是轻量级的,适合于简单的图形、图像处理等任务。例如,在模拟粒子系统时,用OpenGL通用计算API来计算速度、位置、势能等,再快速切换到渲染模式,把整个粒子系统显示出来。相比之下,OpenCL需要比较复杂的set-up,而且和图形渲染之间的相互切换(inter-op)也有较高的执行开销。
需要强调的是,OpenCL虽然是从GPU领域诞生出来,但通用计算框架远不止适用于GPU。同样可以应用在CPU,DSP,FPGA,或其它异构计算的体系架构中。OpenCL在跨平台的功能移植性(functional portability)方面是很好的,但是其性能移植性(performance portibility)往往并不理想。
另一个算是常用、但并不被大多数人知道的通用计算API是Google推出的RenderScript。Google一开始是希望能像DirectX一样,同时支持图形渲染和通用计算。但很快发现,图形渲染抵不过OpenGL,便丢下了渲染,专注于通用计算。所以有人开玩笑说,RenderScript既不是render也不是script。目前,RenderScript主要用在安卓系统中,只有Google自己的应用在使用。但随着下一代通用计算API的发展,RenderScript前途未卜。
阿里的许多业务app在手机端上执行,对GPU的使用一般都是轻量级的。但随着业务功能的增强,特别是AI和机器学习应用的普及,在端上的计算越来越多。之前的图形渲染、通用计算API,不管是OpenCL和OpenGL,还是Renderscript,驱动开销(driver overhead)都比较高。所以提高端上GPU功效、增加电池续航能力是移动GPU的当务之急。即使是在数据中心,能降低驱动程序的开销,提高服务器CPU/GPU效率,对能源、硬件资源的节省也可以带来可观的效益。所以近两三年来,工业界在研究如何降低GPU驱动上投入了大量的人力物力。几大巨头纷纷加入了所谓的“几乎零开销驱动”(almost zero overhead driver,AZOD)的竞争。
- 苹果的Metal API,主要用在iOS和MacOS上
- 微软的DirectX 12,当然还是聚集在windows系统中
- 超微(AMD)推出了Mantle
- Google 也有自己的版本(出于公司的秘密,隐去其名)
- Khronos Group跨平台的Vulkan
经过一番混战和讨价还价,竞争的结果就是AMD和Google各自把自己的ideas和框架工作捐给了Khronos,融合、演变成了现在的Vulkan 1.0。笑到最后的是苹果Metal和微软DirectX 12专用API,以及Khronos Group的跨平台通用Vulkan API。实质上,这三个API的features都是大同小异。
当然,AZOD并不能魔术般的让驱动程序开销一扫而光。他们在实现层面上主要集中在以下几点:
- 减少GPU在命令序列中的状态更新、同步等开销
- 重复使用命令包,并允许增量更新(incremental update)
- 实现多个渲染目标的融合,减少GPU数据的导入、导出
- non-binding 纹理等资源的使用
- 把内存管理、多线程管理等繁琐的任务推到用户层;用户本来就有更好的全局观来管理资源的生命周期
- 把GPU程序(shaders)的编译工作在线下预处理,降低在线编译的开销
再稍微介绍一下Vulkan:
如果想理清Vulkan和OpenGL的关系,可以把Vulkan看成是下一代的OpenGL,即OpenGL 5.0。在Vulkan的命名上,除了希腊神话中的强大火神外,还有5的意思(罗马数字V)。同样,Vulkan也有一个附带的编程语言,叫做SPIR-V (standard portable intermediate representation,SPIR)。V既是5,也是针对Vulkan。不过,SPIR-V在语言的定义上,远超出了图形的范畴,有能力表述通用计算、甚至C++的功能。现在有不少开源项目是基于SPIR-V,以得到更好的移植性。
原文来自:https://yq.aliyun.com/articles/117827?spm=5176.100239.bloglist.96.t8iqI1
本文地址: https://www.linuxprobe.com/gpu-learn.html编辑:任维国,审核员:逄增宝
本文原创地址:https://www.linuxprobe.com/gpu-learn.html编辑:public,审核员:暂无







