| 导读 | BigCode 是一个开放的科学合作组织,致力于开发大型语言模型。近日他们开源了一个名为 SantaCoder 的语言模型,该模型拥有 11 亿个参数,可以用于 Python、Java 和 JavaScript 这几种编程语言的代码生成和补全建议。 |
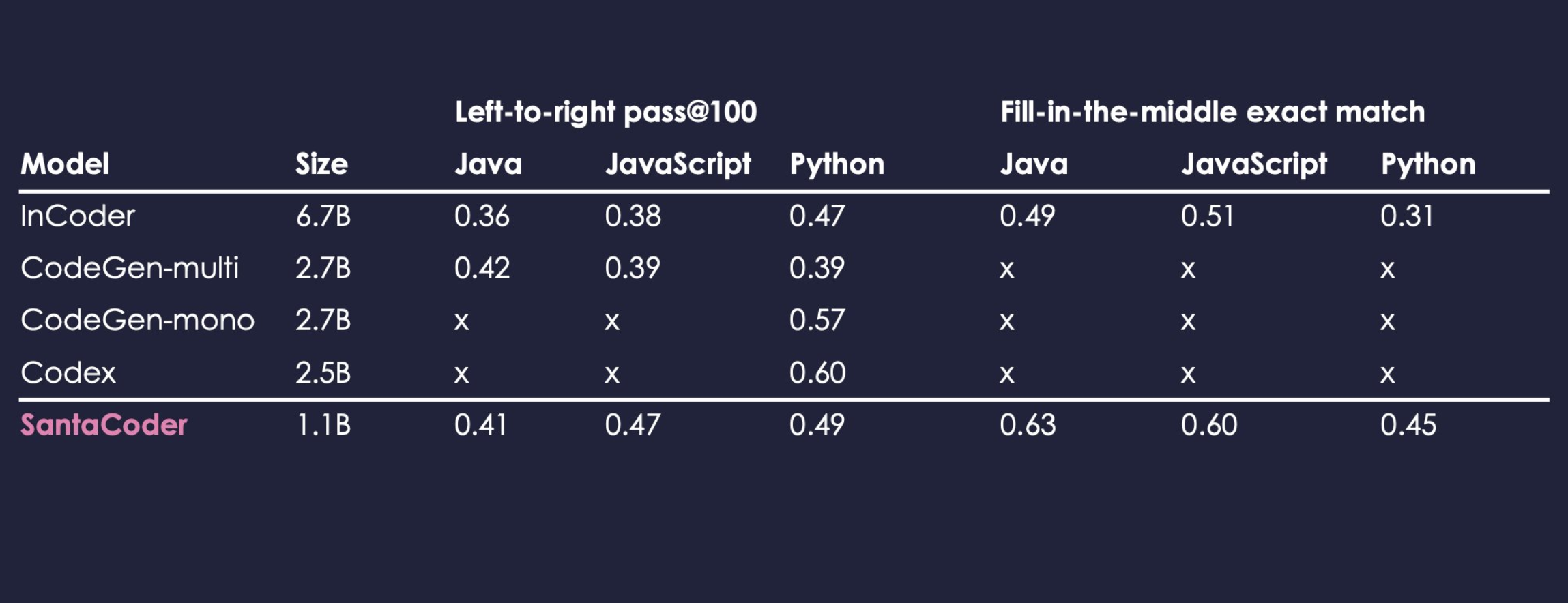
根据官方提供的信息,训练 SantaCoder 的基础是 The Stack(v1.1)数据集,SantaCoder 虽然规模相对较小,只有 11 亿个参数,在参数的绝对数量上低于 InCoder(67 亿)或 CodeGen-multi(27 亿),但 SantaCoder 的表现则是要远好于这些大型多语言模型。不过也正是参数远远不及 GPT-3 等参数超过千亿级别的超大型语言模型,SantaCoder 适用的编程语言范围也比较有限,仅支持 Python、Java 和 JavaScript 三种语言。
为了照顾用户隐私和保证训练质量,在训练模型之前,BigCode 注释了 400 个样本,并建立和不断完善 RegEx 规则,以便在训练前从数据集的代码中删除诸如电子邮件地址、密钥和 IP 地址等敏感信息。
为了让开发者可以放心使用 SantaCoder 生成的代码,BigCode 推出了 Dataset Search 搜索工具。通过这个工具,开发者可以找出代码的来源,以便在 SantaCoder 产生的代码属于某一个项目的情况下,用户能够遵守相应的许可要求。
此外,BigCode 还推出了「Am I in The Stack?」工具,开发者可以检查自己名下的仓库是否是训练数据集的一部分,可以将自己的开源仓库从数据集中删除。
BigCode 目前已经在 Huggingface 网站中提供了 SantaCoder 演示,供任何人研究试用。
原文来自:https://www.oschina.net/news/222809/bigcode-santacoder
本文地址:https://www.linuxprobe.com/bigcode-python-java.html编辑:xiangping wu,审核员:清蒸github
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/