| 导读 | Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。 |
Elasticsearch 是一个基于 Apache Lucene(TM) 的开源搜索引擎。
无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库,并通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
Elasticsearch 不仅仅是 Lucene 和全文搜索,我们还能这样去描述它:
– 分布式的实时文件存储,每个字段都被索引并可被搜索
– 分布式的实时分析搜索引擎
– 可以扩展到上百台服务器,处理 PB 级结构化或非结构化数据
就像很多业务系统是基于 Spring 实现一样,Elasticsearch 和 Lucene 的关系很简单:Elasticsearch 是基于 Lucene 实现的。ES 基于底层这些包,然后进行了扩展,提供了更多的更丰富的查询语句,并且通过 RESTful API 可以更方便地与底层交互。类似 ES 还有 Solr 也是基于 Lucene 实现的。
在应用开发中,用 Elasticsearch 会很简单。但是如果你直接用 Lucene,会有大量的集成工作。
因此,入门 ES 的同学,稍微了解下 Lucene 即可。如果往高级走,还是需要学习 Lucene 底层的原理。因为倒排索引、打分机制、全文检索原理、分词原理等等,这些都是不会过时的技术。
一个 ES Index (索引,比如商品搜索索引、订单搜索索引)集群下,有多个 Node (节点)组成。每个节点就是 ES 的实例。
每个节点上会有多个 shard (分片), P1 P2 是主分片 R1 R2 是副本分片
每个分片上对应着就是一个 Lucene Index(底层索引文件)
Lucene Index 是一个统称。由多个 Segment (段文件,就是倒排索引)组成。每个段文件存储着就是 Doc 文档。
lucene 中,单个倒排索引文件称为 segment。其中有一个文件,记录了所有 segments 的信息,称为 commit point:
文档 create 新写入时,会生成新的 segment。同样会记录到 commit point 里面
文档查询,会查询所有的 segments
当一个段存在文档被删除,会维护该信息在 .liv 文件里面
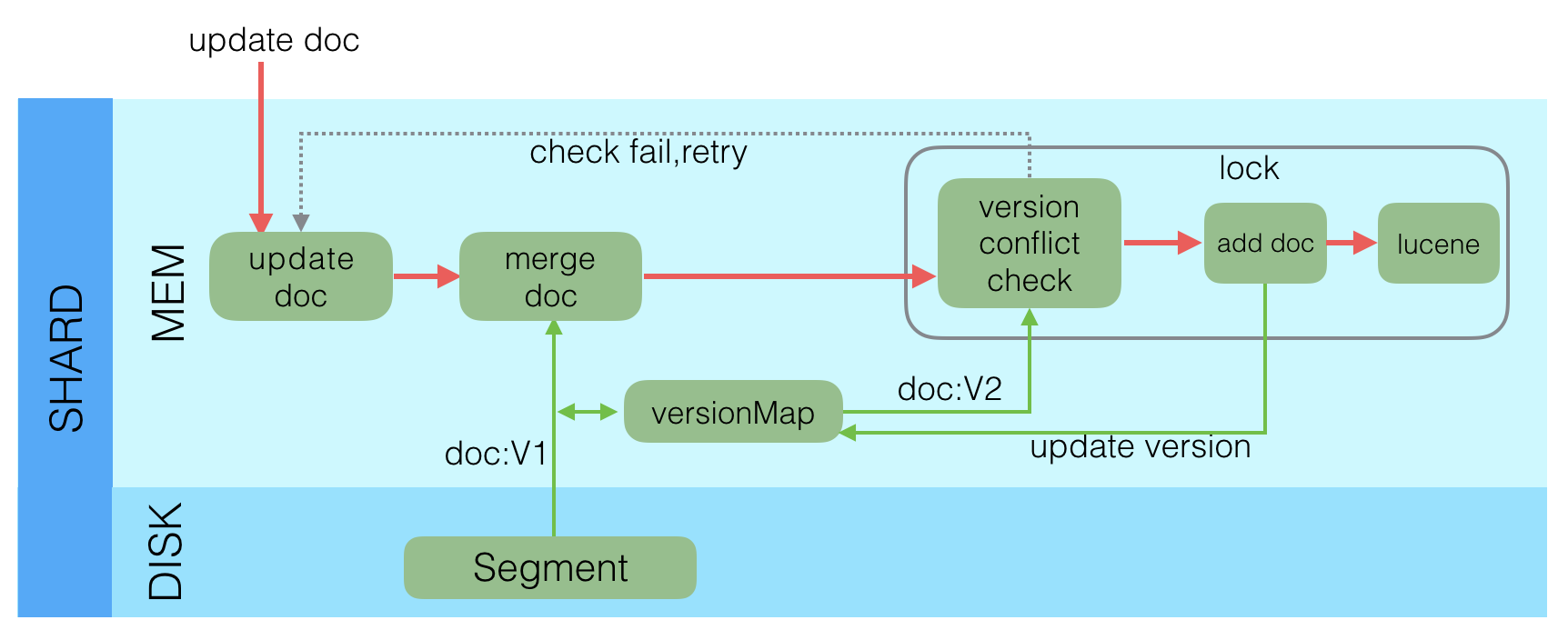
新文档创建或者更新时,进行如下流程:
更新不会修改原来的 segment,更新和创建操作都会生成新的一个 segment。数据哪里来呢?先会存在内存的 bugger 中,然后持久化到 segment 。
数据持久化步骤如下:write -> refresh -> flush -> merge
一个新文档过来,会存储在 in-memory buffer 内存缓存区中,顺便会记录 Translog。
这时候数据还没到 segment ,是搜不到这个新文档的。数据只有被 refresh 后,才可以被搜索到。那么 讲下 refresh 过程
refresh 默认 1 秒钟,执行一次上图流程。ES 是支持修改这个值的,通过 index.refresh_interval 设置 refresh (冲刷)间隔时间。refresh 流程大致如下:
in-memory buffer 中的文档写入到新的 segment 中,但 segment 是存储在文件系统的缓存中。此时文档可以被搜索到
最后清空 in-memory buffer。注意: Translog 没有被清空,为了将 segment 数据写到磁盘
文档经过 refresh 后, segment 暂时写到文件系统缓存,这样避免了性能 IO 操作,又可以使文档搜索到。refresh 默认 1 秒执行一次,性能损耗太大。一般建议稍微延长这个 refresh 时间间隔,比如 5 s。因此,ES 其实就是准实时,达不到真正的实时。
上个过程中 segment 在文件系统缓存中,会有意外故障文档丢失。那么,为了保证文档不会丢失,需要将文档写入磁盘。那么文档从文件缓存写入磁盘的过程就是 flush。写入次怕后,清空 translog。
translog 作用很大:
保证文件缓存中的文档不丢失
系统重启时,从 translog 中恢复
新的 segment 收录到 commit point 中
具体可以看官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.3/indices-flush.html
上面几个步骤,可见 segment 会越来越多,那么搜索会越来越慢?怎么处理呢?
通过 merge 过程解决:
就是各个小段文件,合并成一个大段文件。段合并过程
段合并结束,旧的小段文件会被删除
.liv 文件维护的删除文档,会通过这个过程进行清除
如这个图,ES 写入原理不难,记住关键点即可。
write -> refresh -> flush
– write:文档数据到内存缓存,并存到 translog
– refresh:内存缓存中的文档数据,到文件缓存中的 segment 。此时可以被搜到
– flush 是缓存中的 segment 文档数据写入到磁盘
写入的原理告诉我们,考虑的点很多:性能、数据不丢失等等
原文来自:https://www.bysocket.com/technique/2414.html
本文地址:https://www.linuxprobe.com/elasticsearch-lucene.html编辑:xiangping wu,审核员:逄增宝
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/