T为时间戳的必需元素,它将日期和时间分隔开。
22:14:15.003是24小时制的时间,包括步入下1秒的微秒数(003)。
Z是一个可选元素,指的是UTC时间,不仅Z,这个事例还可以包括一个偏斜量,比如-08:00,这意味着时间从UTC偏斜8小时,即PST时间。
主机名
主机名数组(在前面的事例中对应)指的是主机的名称或发送信息的系统.
应用名
应用名数组(在前面的事例中对应sshd:auth)指的是发送信息的程序的名称.
优先级
优先级数组或简写为pri(在前面的事例中对应)告诉我们这个风波有多紧急或多严峻。它由两个数字数组组成:设备数组和紧急性数组。紧急性数组从代表debug类风波的数字7仍然到代表紧急风波的数字0。设备数组描述了那个进程创建了该风波。它从代表内核信息的数字0到代表本地应用使用的23。
Pri有两种输出形式。第一种是以一个单独的数字表示,可以这样估算:先用设备数组的值减去8,再加上紧急性数组的值:(设备数组)(8)+(紧急性数组)。第二种是pri文本,将以“设备数组.紧急性数组”的字符串格式输出。后一种格式更便捷阅读和搜索,但抢占更多的储存空间。
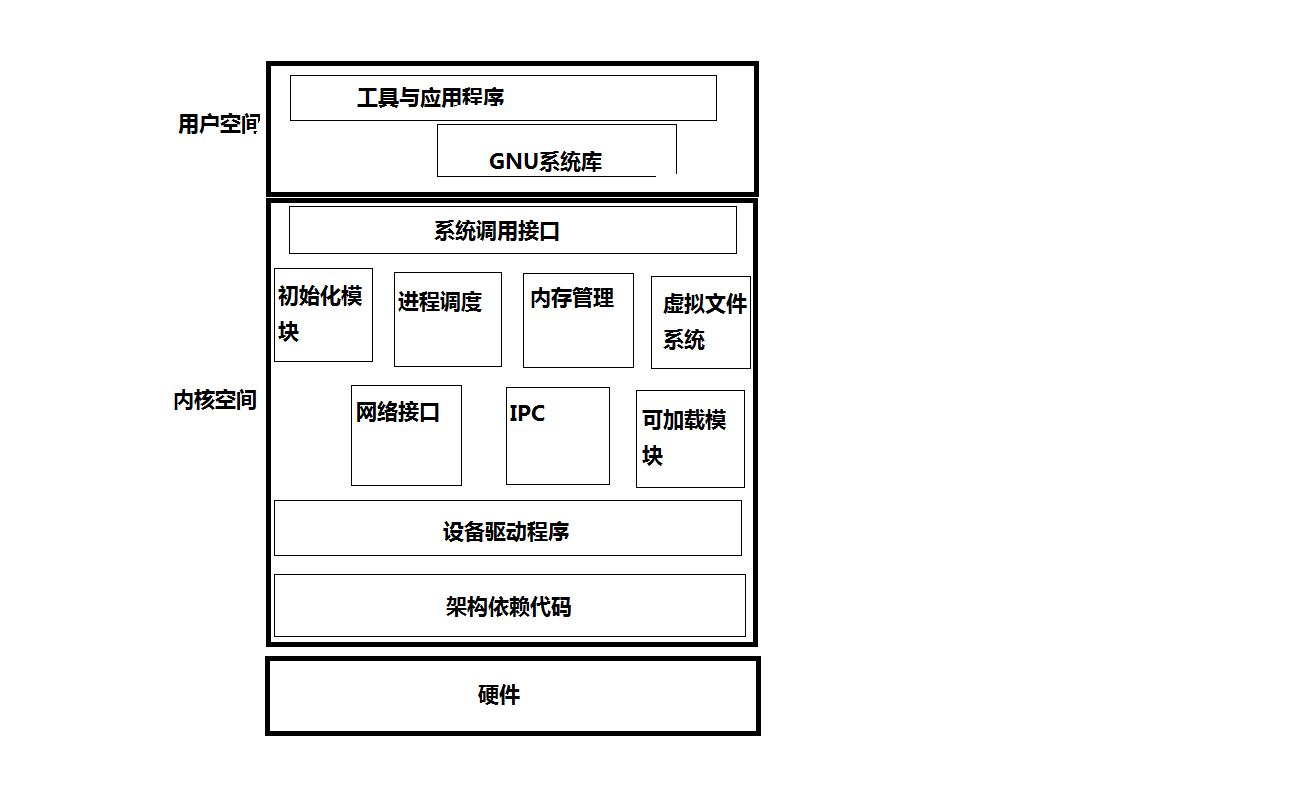
剖析Linux日志
日志中有大量的信息须要你处理,虽然有时侯想要提取并非想像中的容易。在这篇文章中我们会介绍一些你如今能够做的基本日志剖析事例(只须要搜索即可)。我们还将涉及一些更中级的剖析,但这种须要你前期努力作出适当的设置,后期才能节约好多时间。对数据进行中级剖析的事例包括生成汇总计数、对有效值进行过滤,等等。
我们首先会向你展示怎样在命令行中使用多个不同的工具,之后展示了一个日志管理工具怎么能手动完成大部份艰巨工作因而致使日志剖析显得简单。
用Grep搜索
搜索文本是查找信息最基本的形式。搜索文本最常用的工具是grep。这个命令行工具在大部份Linux发行版中都有,它容许你用正则表达式搜索日志。正则表达式是一种用特殊的语言写的、能辨识匹配文本的模式。最简单的模式就是用冒号把你想要查找的字符串括上去。
正则表达式
这是一个在Ubuntu系统的认证日志中查找“userhoover”的反例:
复制代码
代码如下:
$grep"userhoover"/var/log/auth.log
Acceptedpasswordforhooverfrom10.0.2.2port4792ssh2
pam_unix(sshd:session):sessionopenedforuserhooverby(uid=0)
pam_unix(sshd:session):sessionclosedforuserhoover
打造精确的正则表达式可能很难。诸如,假如我们想要搜索一个类似端口“4792”的数字,它可能也会匹配时间戳、URL以及其它不须要的数据。Ubuntu中下边的事例,它匹配了一个我们不想要的Apache日志。
复制代码
代码如下:
$grep"4792"/var/log/auth.log
Acceptedpasswordforhooverfrom10.0.2.2port4792ssh2
74.91.21.46--[31/Mar/2015:19:44:32+0000]"GET/scripts/samples/search?q=4972HTTP/1.0"404545"-""-”
环绕搜索
另一个有用的小方法是你可以用grep做环绕搜索。这会向你展示一个匹配上面或旁边几行是哪些。它能帮助你调试造成错误或问题的东西。B选项展示后面几行,A选项展示前面几行。举个事例,我们晓得当一个人以管理员员身分登入失败时,同时她们的IP也没有反向解析,也就意味着她们可能没有有效的域名。这十分可疑!
复制代码
代码如下:
$grep-B3-A2'Invaliduser'/var/log/auth.log
Apr2817:06:20ip-172-31-11-241sshd[12545]:reversemappingcheckinggetaddrinfofor[216.19.2.8]failed-POSSIBLEBREAK-INATTEMPT!
Apr2817:06:20ip-172-31-11-241sshd[12545]:Receiveddisconnectfrom216.19.2.8:11:ByeBye[preauth]
Apr2817:06:20ip-172-31-11-241sshd[12547]:Invaliduseradminfrom216.19.2.8
Apr2817:06:20ip-172-31-11-241sshd[12547]:input_userauth_request:invaliduseradmin[preauth]
Apr2817:06:20ip-172-31-11-241sshd[12547]:Receiveddisconnectfrom216.19.2.8:11:ByeBye[preauth]
Tail
你也可以把grep和tail结合使用来获取一个文件的最后几行linux操作系统版本,或则跟踪日志并实时复印。这在你做交互式修改的时侯十分有用,比如启动服务器或则测试代码修改。
复制代码
代码如下:
$tail-f/var/log/auth.log|grep'Invaliduser'
Apr3019:49:48ip-172-31-11-241sshd[6512]:Invaliduserubntfrom219.140.64.136
Apr3019:49:49ip-172-31-11-241sshd[6514]:Invaliduseradminfrom219.140.64.136
关于grep和正则表达式的详尽介绍并不在本手册的范围,但Ryan’sTutorials有更深入的介绍。
日志管理系统有更高的性能和更强悍的搜索能力。它们一般会索引数据并进行并行查询,因而你可以很快的在几秒内能够搜索GB或TB的日志。相比之下,grep就须要几分钟,在极端情况下可能甚至几小时。日志管理系统也使用类似Lucene的查询语言,它提供更简单的句型来检索数字、域以及其它。
用Cut、AWK、和Grok解析
Linux提供了多个命令行工具用于文本解析和剖析。当你想要快速解析少量数据时特别有用,但处理大量数据时可能须要很长时间。
Cut
cut命令容许你从有分隔符的日志解析数组。分隔符是指能分开数组或通配符对的等号或冒号等。
假定我们想从下边的日志中解析出用户:
复制代码
代码如下:
pam_unix(su:auth):authenticationfailure;logname=hooveruid=1000euid=0tty=/dev/pts/0ruser=hooverrhost=user=root
我们可以像下边这样用cut命令获取用等号分割后的第八个数组的文本。这是一个Ubuntu系统上的反例:
复制代码
代码如下:
$grep"authenticationfailure"/var/log/auth.log|cut-d'='-f8
root
hoover
root
nagios
nagios
AWK
另外,你也可以使用awk,它能提供更强悍的解析数组功能。它提供了一个脚本语言,你可以过滤出几乎任何不相干的东西。
比如,假定在Ubuntu系统中我们有下边的一行日志linux 系统日志分析,我们想要提取登陆失败的用户名称:
复制代码
代码如下:
Mar2408:28:18ip-172-31-11-241sshd[32701]:input_userauth_request:invaliduserguest[preauth]
你可以像下边这样使用awk命令。首先,用一个正则表达式/sshd.*invaliduser/来匹配sshdinvaliduser行。之后用{print$9}按照默认的分隔符空格复印第九个数组。这样就输出了用户名。
复制代码
代码如下:
$awk'/sshd.*invaliduser/{print$9}'/var/log/auth.log
guest
admin
info
test
ubnt
你可以在Awk用户手册中阅读更多关于怎么使用正则表达式和输出数组的信息。
日志管理系统
日志管理系统促使解析显得愈发简单,使用户能快速的剖析好多的日志文件。她们能手动解析标准的日志格式,例如常见的Linux日志和Web服务器日志。这能节约好多时间,由于当处理系统问题的时侯你不须要考虑自己写解析逻辑。
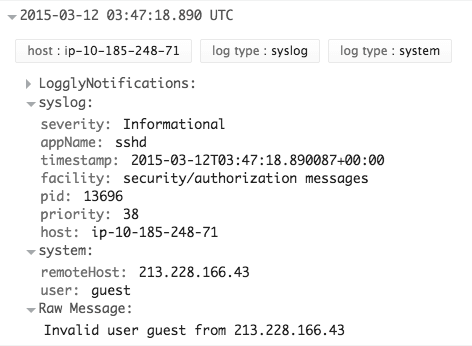
下边是一个sshd日志消息的反例,解析出了每位remoteHost和user。这是Loggly中的一张截图,它是一个基于云的日志管理服务。
你也可以对非标准格式自定义解析。一个常用的工具是Grok,它用一个常见正则表达式库,可以解析原始文本为结构化JSON。下边是一个Grok在Logstash中解析内核日志文件的例子配置:
复制代码
代码如下:
filter{
grok{
match=>{"message"=>"%{CISCOTIMESTAMP:timestamp}%{HOST:host}%{WORD:program}%{NOTSPACE}%{NOTSPACE}%{NUMBER:duration}%{NOTSPACE}%{GREEDYDATA:kernel_logs}"
右图是Grok解析后输出的结果:
用Rsyslog和AWK过滤
过滤促使你能检索一个特定的数组值而不是进行全文检索。这使你的日志剖析愈发确切,由于它会忽视来自其它部份日志信息不须要的匹配。为了对一个数组值进行搜索,你首先须要解析日志或则起码有对风波结构进行检索的形式。
怎么对应用进行过滤
一般,你可能只想看一个应用的日志。假如你的应用把记录都保存到一个文件中都会很容易。假如你须要在一个集聚或集中式日志中过滤一个应用都会比较复杂。下边有几种方式来实现:
用rsyslog守护进程解析和过滤日志。下边的反例将sshd应用的日志写入一个名为sshd-message的文件,之后扔掉风波便于它不会在其它地方重复出现。你可以将它添加到你的rsyslog.conf文件中测试这个反例。
复制代码
代码如下:
:programname,isequal,“sshd”/var/log/sshd-messages
&~
用类似awk的命令行工具提取特定数组的值,比如sshd用户名。下边是Ubuntu系统中的一个反例。
复制代码
代码如下:
$awk'/sshd.*invaliduser/{print$9}'/var/log/auth.log
guest
admin
info
test
ubnt
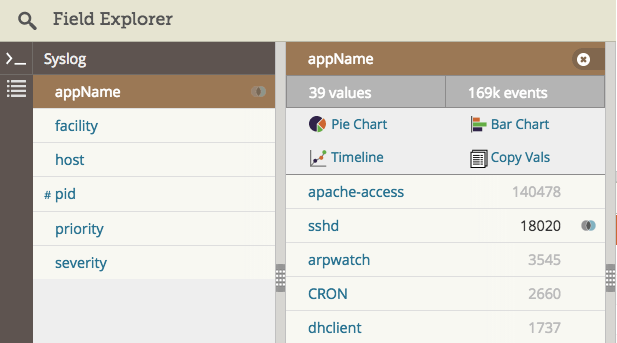
用日志管理系统手动解析日志,之后在须要的应用名称上点击过滤。下边是在Loggly日志管理服务中提取syslog域的截图。我们对应用名称“sshd”进行过滤,如维恩图图标所示。
怎么过滤错误
一个人最希望见到日志中的错误。不幸的是,默认的syslog配置不直接输出错误的严重性linux 系统日志分析,也就促使无法过滤它们。
这儿有两个解决该问题的方式。首先,你可以更改你的rsyslog配置,在日志文件中输出错误的严重性linux学习,致使以便查看和检索。在你的rsyslog配置中你可以用pri-text添加一个模板,像下边这样:
复制代码
代码如下:
":%timegenerated%,%HOSTNAME%,%syslogtag%,%msg%n"
这个反例会根据下边的格式输出。你可以看见该信息手指示错误的err。
复制代码
代码如下:
:Mar1118:18:00,hoover-VirtualBox,su[5026]:,pam_authenticate:Authenticationfailure
你可以用awk或则grep检索错误信息。在Ubuntu中,对这个反例,我们可以用一些句型特点,比如.和>,它们只会匹配这个域。
复制代码
代码如下:
$grep'.err>'/var/log/auth.log
:Mar1118:18:00,hoover-VirtualBox,su[5026]:,pam_authenticate:Authenticationfailure
你的第二个选择是使用日志管理系统。好的日志管理系统能手动解析syslog消息并抽取错误域。它们也容许你用简单的点击过滤日志消息中的特定错误。
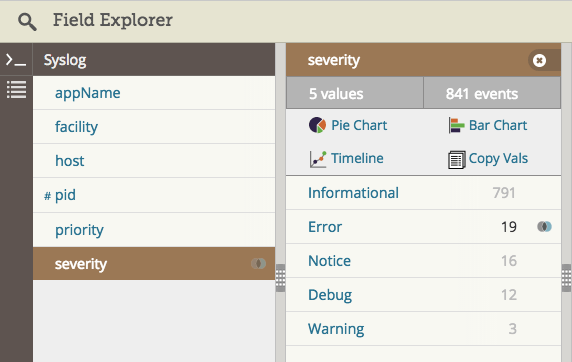
下边是Loggly中一个截图,显示了高亮错误严重性的syslog域,表示我们正在过滤错误:
«
»
本文原创地址:https://www.linuxprobe.com/fxlrzzdjbrzf.html编辑:刘遄,审核员:暂无