


Serverlessconf 的所有与会者依然还在忙着给“无服务器”下定义,并达成了一些共识:
- 无服务器不仅仅是函数即服务 (FaaS, Functions As A Service),还包含诸如数据库、身份验证、API 网关、编排,甚至具体到某一领域的其他服务,例如视频转码即服务或认知服务。总的来说,所有与这些服务有关的基础架构都不需要我们自行管理。
- 无服务器意味着(近似于)100% 的利用率。如果和 PaaS 相比的话,PaaS 应用程序要么以特定的规模运行,要么以非常慢的速度进行伸缩,但会因为伸缩操作本身造成一定的开销(例如有未使用的实例处于闲置状态,等待接受请求)。作为对比,如果无服务器服务暂不使用,此时不会产生任何成本,但如果有必要可以(几乎)瞬时伸缩至数百万用户,服务的成本直接取决于使用量。
会上的另一个重要议题是:无服务器应用促成了一种围绕事件本身,而非围绕数据来设计的架构。将应用程序订阅到某个事件队列,这是管理服务通信的一种好方法,借此我们可以轻松地为现有队列添加新服务,或修改 / 添加功能,而不需要将数据流直接绑定给应用,进而产生强耦合。
Rob Gruhl 介绍了 Nordstrom 公司正在从事的一个有趣项目:他们正在通过一个集中且统一的事件日志管理零售系统内部的数据流动。应用程序可以通过流生成和使用事件,任何需要对当前状态获得高性能视图的应用程序均可订阅至事件流,借此构建自己的状态数据库(一种数据库视图)。随后即可根据需求为请求提供服务。同时这些应用还可生成供其它服务使用的事件。这样的方式彻底避免了为实现某些状态的中心化存储而使用核心数据库系统的做法,可在改善伸缩性的同时实现微服务之间的解耦。
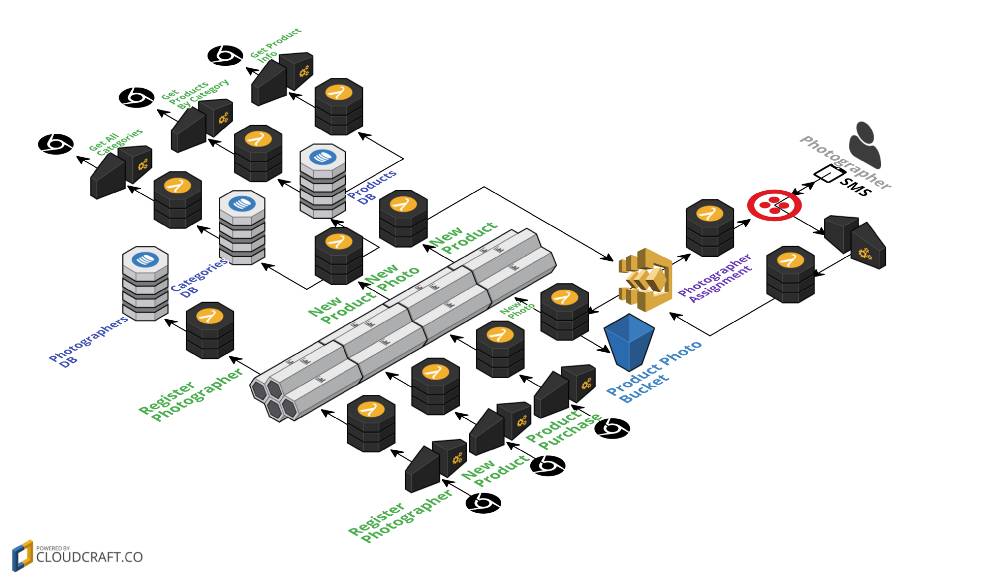
他们提供了一个名为 Hello Retail 的演示应用,摄影师可以借助该应用为新产品拍照。当新产品加入后,系统会从已知摄影师清单中选择一位摄影师,发送手机短信请求对方拍摄新照片。当摄影师(用短信)回复后,系统会开始处理照片,将其加入图库,随后注册为新产品对应的照片。
来自 Capital One 的 Srini Uppalapati 介绍了 Capital One 的核心金融系统,他们目前正在将这套系统迁移到云端,并且这一过程中大量使用了无服务器相关技术。他们核心交易系统的迁移主要分为两个阶段:
- 循序渐进撤销通过大型机系统执行的读取操作:逐渐将大型机系统产生的事件以流的形式发送至云端数据库,并供面向用户的应用和数据科学家使用。
- 消除消费者应用中的写操作,将核心业务逻辑搬入云端。
目前他们已经完成了第一阶段的任务。在 Srini 所介绍的架构中,他们使用 AWS Lambda 对老数据以及来自大型机的实时事件进行批处理,并将数据装入 S3 以便归档,消费者应用使用了 DynamoDB,分析工作使用了 Redshift。
这个系统在架构和应用层面有一些极为有趣的特点,直接使用“一手”事件是一种对逻辑和状态进行解耦的强大方法:单向数据流使得一切变得更简单。在应用层面上,以 ELM 架构和 React/Redux 为例,通过迁入云端,我们可以将云函数与核心事件流配合使用,打造实用的大规模云应用程序。
上文曾经提到,Nordstrom 和 Capital One 正在通过几个重要项目证明无服务器技术在企业领域的运用前景。最令我吃惊的是,Serverlessconf 大会上还提到了很多其他正在这样做的大企业,他们正在快速接受无服务器技术。
我认为,他们能如此快接受这种技术,原因之一在于很多企业已经开始迁往云端,既然云供应商提供了无服务器相关产品,并且这种技术可以进一步降低成本,他们自然会愿意接受。例如 Capital One 的 Srini 介绍说,通过使用云端无服务器技术,他们大幅节约了成本。目前交易中心每年运营成本约为 9.5 万美元(考虑到客户数高达 4500 万,这样的成本已经相当低了)。
为了满足企业的这类需求,不仅 AWS,目前所有云供应商都在无服务器产品方面进行了巨大的投入。其他云供应商(Google、微软,以及 IBM)也介绍了自家的 FaaS 和无服务器编排产品。
Mike Roberts 通过一场精彩的演讲介绍了应用开发者如何借助无服务器技术变得更加以客户为中心,而无须过度关注技术问题本身。现代化敏捷(塑造更出色的人员,持续不断地提供价值,让安全成为先决条件,更快速地尝试和学习)在无服务器技术的帮助下变得更易于实现,开发者再也不需要重新解决已被其他开发者解决了无数遍的相同问题(如何进行身份验证,如何伸缩等),这样他们就可以更专注地为自己的客户提供价值。借此,生产发布再也不需要耗费数天甚至数周时间,几小时就够了。
考虑到:
“我们的大部分想法其实都很糟糕” — Jeff Patton
我们应当尽可能尝试更多想法。感谢无服务器技术,“试错”成本得以大幅降低!
无服务器技术在这方面已经有很多成功先例,例如 Marcia Villalba 介绍了 Toons.tv 是如何迁移至无服务器技术的。他们在面向云环境重新设计架构后,成本大幅降低,而这一切都是由几名不熟悉无服务器技术的工程师组成的小团队,在几个月的时间里顺利完成的。Marcia 认为他们的成功主要归功于每周一次的研讨会,大家借此交流讨论新技术的学习心得,并通过测试进行概念验证。
有一种普遍共识认为,相比云供应商提供的服务,周边工具的发展有些落后了。Florian Motlik 详细介绍了 AWS CLI 工具的不足之处。其他云供应商也面临类似情况,他们往往在无服务器运行时方面投入巨大,但总是会忽视部署、监视和本地测试等过程中必不可少的工具。
基本上,这也意味着用户与云供应商之间的任何交互都必须通过第三方工具进行,例如没人会通过 AWS CLI 进行无服务器部署,大家更愿意通过第三方技术将云供应商生硬的接口抽象为简单易用的应用程序部署框架(例如 Serverless Framework、claudiaJS,以及适合新手的 zappa)。
为了解决这种问题,AWS 发布了 Serverless Application Model (SAM)。SAM 是一种 CloudFormation 之上的抽象层,可大幅简化 Serverless Applications 的创建工作,但 AWS CLI 在这方面依然不够成熟(个人观点)。
很多人还认为,无服务器应用的监视和调试方面也缺乏必要的支持,面对基于事件的架构更是如此(“我的函数无法运行但不知道原因!”以及“为什么不能对运行中的无服务器函数进行实时调试??”)。
我这并不是在抱怨缺乏交互式调试能力,因为交互式调试实际上可能是一种反面模式 (Anti-pattern),但如果你想要这样做,微软已经支持通过 Visual Studio 或 Visual Studio Code 对 Azure 云函数进行实时调试(虽然演示过程看着有点不靠谱)。如果想避免交互式调试,那就写单元测试吧。
另外,所有云供应商都开始在监视方面发力。Amazon X-Ray 就是一种非常实用的监视技术,通过与 AWS SDK 集成,可提供有关集成点,即实时架构示意图的实时图表 (Live graph) 和分析能力。如果你在自己的服务调用中使用了 AWS SDK,基本上就可以免费使用该技术。
讨论的另一个重点在于,很多团队依然在探寻无服务器应用开发的最佳模式。传统上,我们很容易理解特定应用所涉及的相关领域,因为所有内容都位于同一个服务器实例中。你可以启动一个本地实例,准备好所有依赖项,开发过程中在本地执行各种探索式测试。然而对于无服务器开发,通常我们会被紧密绑定至云供应商(服务越“微型”,绑定的程度越高),为了测试应用能否端到端运行,通常还需要对应用程序进行实际的部署(可能会涉及多个云服务组件),甚至要在开发过程中进行部署。很多因素会要求我们必须能够在本地进行探索式测试,但如何对测试中的应用进行隔离,目前并没有任何行之有效的模式,通常到最后我们往往会面对一系列同时在本地和云端运行,“拼凑”出来的测试应用。这方面目前已经有了一些解决方案,例如 Atlassian AWS Local Stack,可以在用户的本地计算机上提供一套功能完备的 AWS 栈。然而为何要用它,而不是直接部署到开发环境,这个问题依然存在争议。
无服务器计算还面临一个大问题:难以通过编排大量 Lambda 函数进而在云中创建数据管道。事件流是将 Lambda 函数连接在一起的一种方法,然而通常我们还需要更高级的功能,例如等待条件或并行处理能力。
AWS 和 Azure 都曾演示过自己的无服务器编排技术:AWS Step Functions,以及 Azure Logic Apps,这两种技术看起来都很有吸引力。
Azure Logic Apps 提供了超过 250 种适用于其他 Azure 产品,以及第三方产品的连接器。虽然华丽的用户界面让我觉得它不太靠谱,但该技术以 JSON 形式的脚本 DSL 支撑,演示效果很出彩,他们将实时推文连接到了微软的情绪分析服务,借此围绕特定话题实时进行了推文情绪分析……所有操作均在 45 分钟的演示内完成(当然很多代码是复制粘贴的)。
我还不太确定该如何以足够可靠的方式应用这些工作流编排服务(如何对其进行测试和部署?),不过感觉上它们会成为无服务器技术不可分割的一部分。
我很想亲自见证这些工作流服务如何进一步完善成为功能完备的平台。如果有更好的语言(例如 JavaScript 或 Swift)可以编译为“AWS 云计算机语言”,并直接在某种抽象的计算层上运行,又何必使用 JSON DSL 来写脚本。随后可由 AWS 管理所有底层服务器及其状态,用户无需考虑任何有关最长运行时间或最大内存数的限制,只需要严格按照用量来付费。
文章来自微信公众号:细说云计算
原文来自:http://www.yunweipai.com/archives/18197.html
本文地址:https://www.linuxprobe.com/no-servers-ideas.html编辑员:郭建鹏,审核员:逄增宝
本文原创地址:https://www.linuxprobe.com/no-servers-ideas.html编辑:roc_guo,审核员:暂无







