

| 导读 | 对话智能平台 Observe.AI 宣布推出具有 300 亿参数容量的联络中心大型语言模型 (Contact Center LLM),以及旨在提高代理性能的生成式 AI 套件。 |
该公司声称,与 GPT 等模型相比,其专有的 LLM 是在大量真实世界的联络中心交互数据集上进行了训练,能够处理为联络中心团队定制的各种基于 AI 的任务(呼叫汇总、自动 QA、辅导等)。Observe.AI 强调,其模型的独特价值在于它为用户提供的校准和控制。该平台允许用户对模型进行微调和定制,以适应他们特定的联络中心要求。
“LLM 使用不同数量的参数(7B、13B 和 30B 参数)进行训练,以最大限度地提高联络中心的性能。根据初步测试,我们的 Contact Center LLM 被发现在自动总结对话方面比 GPT3.5 准确 35%,在通话期间情绪分析的准确性提高了 33%。”
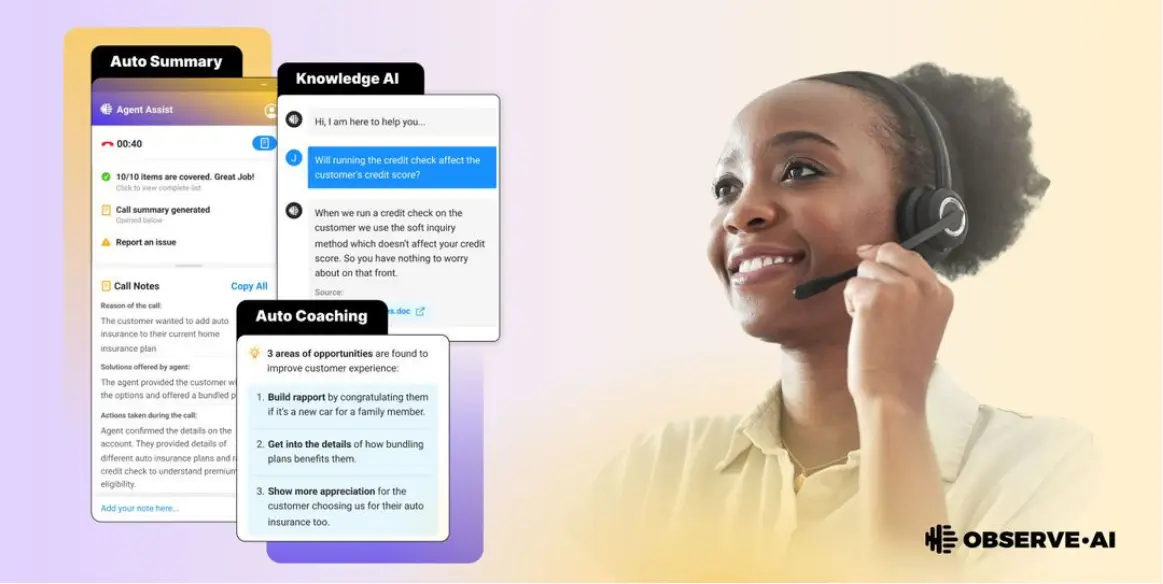
凭借其 LLM 的功能,Observe.AI 的生成式 AI 套件致力于提高提高所有客户互动的代理性能:电话和聊天、查询、投诉以及联络中心团队处理的日常对话。Observe.AI 的 CEO Swapnil Jain 称,“我们的 LLM 在联络中心交互的特定领域数据集上接受了广泛的训练。训练过程涉及利用从 Observe.ai 在过去五年中处理的数亿对话中提取的大量数据点。”
他强调了指令数据集中质量和相关性的重要性,该数据集包含数百条针对直接适用于联络中心用例的各种任务的精选指令。Jain 表示,这种细致的数据集管理方法提高了 LLM 提供行业所需的准确且符合上下文的响应的能力。
Observe.ai 声称其专有模型在一致性和相关性方面超越 GPT 标志着重大进步。“我们的 LLM 只训练完全编辑了任何敏感客户信息和 PII 的数据。我们在这方面的编辑基准堪称行业典范 —— 我们在 1 亿次通话中避免了 1.5 亿次敏感信息的过度编辑,报告的错误少于 500 次。这确保敏感信息得到保护,隐私和合规性得到维护,同时为 LLM 训练保留最多的信息。”
Jain 还透露,该公司已经实施了一个强大的数据协议来存储所有客户数据(包括 LLM 生成的数据),完全符合监管要求。每个客户 / 账户都分配了一个专用存储分区,确保每个客户 / 账户的数据加密和唯一标识。
原文来自:https://www.oschina.net/news/246226/observe-ai-30-billion-parameter-contact-center-llm
本文地址:https://www.linuxprobe.com/observe-linux-play.html编辑:xiangping wu,审核员:清蒸github
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/







