

| 导读 | 在本教程中,将Python3和openpyxl库一起使用来操作 Excel 表格。 |
本文将介绍如下操作:
- 如何在内存中创建工作簿
- 如何从工作簿中检索、创建、复制、移动和删除工作表
- 如何从文件创建工作簿
- 如何访问一系列单元格
- 如何遍历行和列
在Centos8中有如下两种方式安装openpyxl库:
方法一,使用yum包管理器安装:
[root@localhost ~]# yum -y install python3-openpyxl
方法二,使用pip命令安装:
[root@localhost ~]# pip3 install openpyxl
创建工作簿,我们所要做的就是导入并使用 Workbook 类。当我们创建 Workbook 类的实例时,默认情况下也会创建一个新的电子表格。我们可以通过 active 属性访问它:
[root@localhost ~]# python3 >>> from openpyxl import Workbook >>> workbook = Workbook() >>> sheet = workbook.active >>>
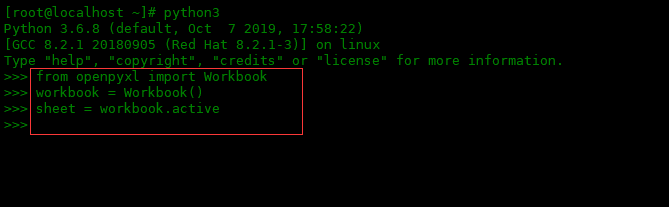
创建新表格时,它不包含任何单元格。它们是即时创建的,因此最好直接访问它们以避免浪费内存。我们可以像引用字典键一样引用表格的单元格。例如,要获取 'A1' 单元格的值,我们可以这样写:
>>> a1_value = sheet['A1'].value >>> print(a1_value) None
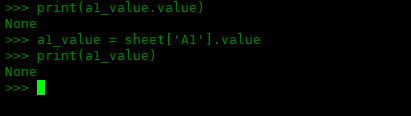
使用print()打印A1单元格的值,因为没有数据,所以返回值为None
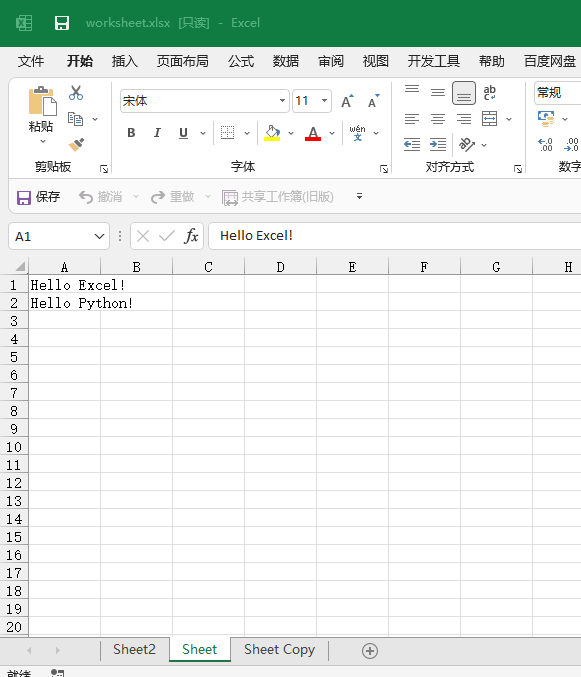
如果要为一个单元格赋值,我们可以这样写:
>>> sheet['A1'] = "Hello Excel!"
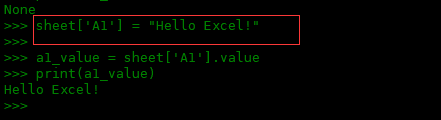
然后重新给a1_value赋值,然后打印,可以看到A1单元格的内容了。
访问单元格的另一种方法是使用 Worksheet 对象的 cell() 方法,并将行/列坐标作为参数传递:
>>> a1_value = sheet.cell(row = 1, column = 1).value >>> print(a1_value) Hello Excel!

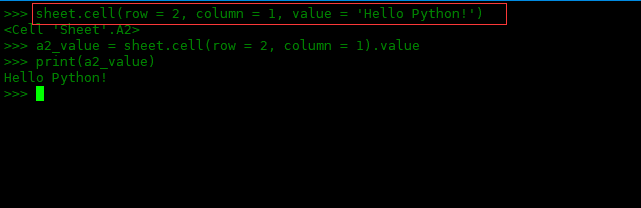
使用cell()填充内容:
>>> sheet.cell(row = 2, column = 1, value = 'Hello Python!') <cell 'Sheet'.A2>
保存我们创建的工作表,我们要做的就是使用 Workbook 对象的 save() 方法,并将目标文件的名称作为参数传递。例如,要将工作表保存为 worksheet.xlsx,我们将运行:
>>> workbook.save('worksheet.xlsx')
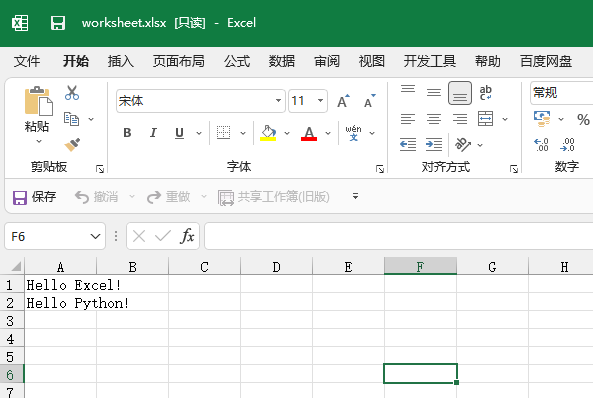
一旦我们调用此方法,就会在我们的系统上创建一个具有指定名称的文件。
在前面的示例中,我们看到了如何访问工作簿的活动电子表格。然而,一个工作簿可以包含多个工作表,那么如果我们想创建一个新的工作表怎么办?我们可以通过 Workbook 的create_sheet 方法来实现:
>>> sheet2 = workbook.create_sheet('Sheet2')
>>> sheet2 = workbook['Sheet2']
>>> print(workbook.sheetnames)
['Sheet', 'Sheet2']
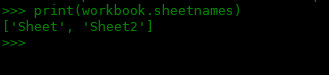
通过使用workbook的sheetnames方法来查看工作簿中的所有工作表。
create_sheet 方法接受两个可选参数:title 和 index。我们可以使用title来为新工作表分配一个名称,而后者index来指定应该在什么位置插入工作表。在上面的示例中,我们使用“Sheet2”作为标题创建了一个新工作表。
将默认激活的工作表复制成副本,我们可以使用 copy_worksheet 方法,将应复制的工作表作为参数传递。例如,要复制活动工作表:
>>> print(workbook.active) <worksheet "Sheet"> >>> sheet_copy = workbook.copy_worksheet(workbook.active)
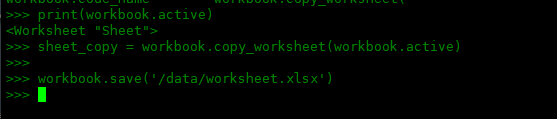
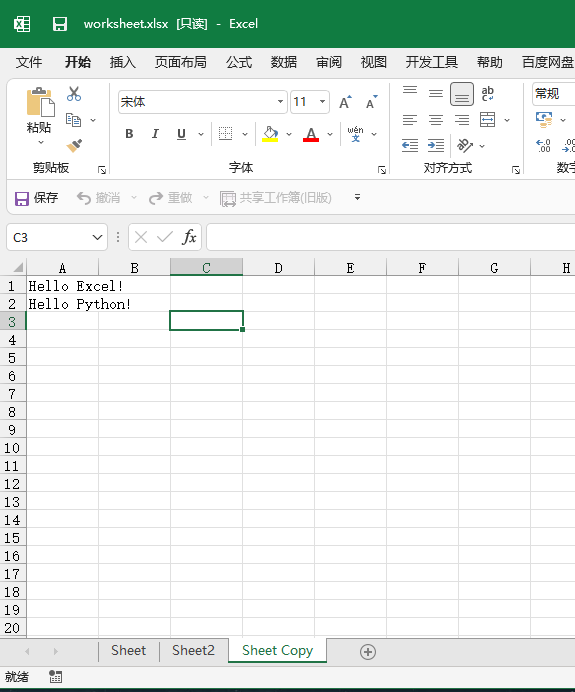
下面再将Sheet2工作表复制一个副本:
>>> sheet_copy = workbook.copy_worksheet(sheet2)
>>> workbook.save('/data/worksheet.xlsx')
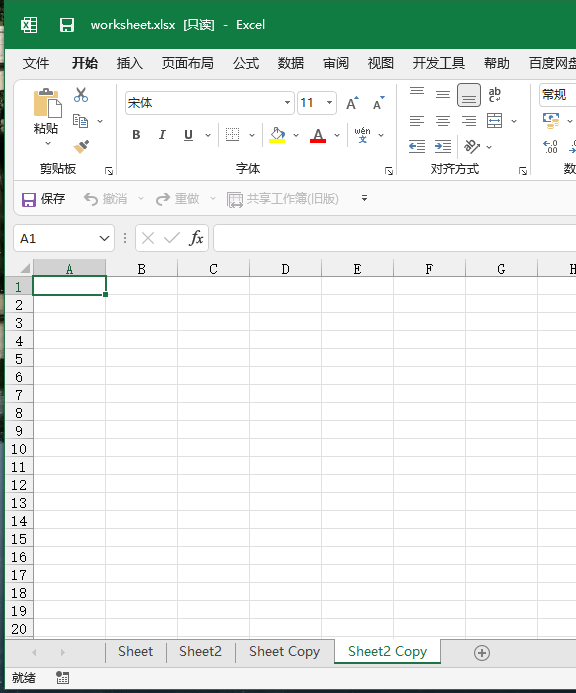
要将现有工作表移动到工作簿中的确定位置,我们可以使用 move_sheet 方法,该方法接受两个参数。第一个 sheet 是必需的,是我们想要移动的工作表,第二个是可选的(默认为 0),是用于指定工作表位置的偏移量。让我们看一个例子。在这种情况下,默认工作表“Sheet”是工作簿中的第一个。要将其移动到第二个位置,我们可以这样写:
>>> workbook.move_sheet(workbook["Sheet"], 1) >>> print(workbook.sheetnames) ['Sheet2', 'Sheet', 'Sheet Copy', 'Sheet2 Copy']

可以使用print(workbook.sheetnames)来查看工作表的顺序。
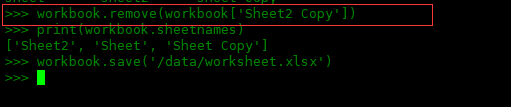
要从工作簿中删除工作表,我们使用 Workbook 类的 remove() 方法。该方法接受一个强制参数,即表示我们要删除的工作表的对象。假设我们想从我们的工作簿中删除“Sheet2 Copy”工作表,我们会写:
>>> workbook.remove(workbook['Sheet2 Copy'])
>>> print(workbook.sheetnames)
['Sheet2', 'Sheet', 'Sheet Copy']
>>> workbook.save('/data/worksheet.xlsx')
>>>
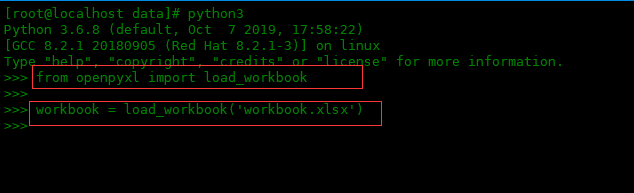
使用 openpyxl 读取现有的 excel 表格文件非常简单。我们所要做的就是从库中加载 load_workbook 函数。这个函数唯一的强制参数是filename,必须是我们要打开的文件的路径。假设这个文件叫做workbook.xlsx:
>>> from openpyxl import load_workbook
>>>
>>> workbook = load_workbook('workbook.xlsx')
>>>
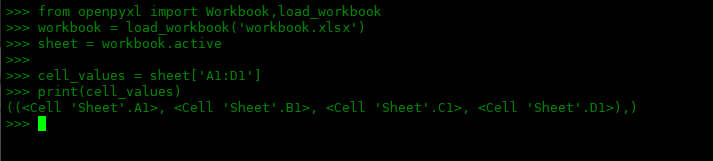
如果我们想获取一系列单元格的值而不是单个单元格的值怎么办?我们所要做的就是使用以下语法指定范围:
>>> cell_values = sheet['A1:D1']
指定范围的结果将是一个元组,其中包含指定的每一行的元组。在上面的例子中,只有一行,因为我们指定了从 A1 到 D1 的单元格(它们确实在同一行),所以结果是:
>>> print(cell_values) ((<cell 'Sheet'.A1>, <cell 'Sheet'.B1>, <cell 'Sheet'.C1>, <cell 'Sheet'.D1>),)
如果想要获取多行多列的单元格,我们可以这样写:
>>> cell_values = sheet['A1':'D5'] >>> print(cell_values) ((<cell 'Sheet'.A1>, <cell 'Sheet'.B1>, <cell 'Sheet'.C1>, <cell 'Sheet'.D1>), (<cell 'Sheet'.A2>, <cell 'Sheet'.B2>, <cell 'Sheet'.C2>, <cell 'Sheet'.D2>), (<cell 'Sheet'.A3>, <cell 'Sheet'.B3>, <cell 'Sheet'.C3>, <cell 'Sheet'.D3>), (<cell 'Sheet'.A4>, <cell 'Sheet'.B4>, <cell 'Sheet'.C4>, <cell 'Sheet'.D4>), (<cell 'Sheet'.A5>, <cell 'Sheet'.B5>, <cell 'Sheet'.C5>, <cell 'Sheet'.D5>))

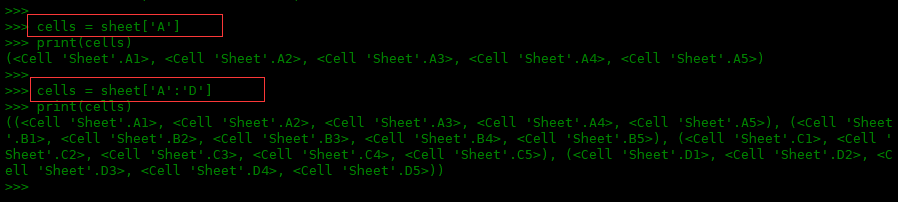
如果想显示指定列的所有数据可以这样写:
>>> cells = sheet['A'] >>> print(cells) (<cell 'Sheet'.A1>, <cell 'Sheet'.A2>, <cell 'Sheet'.A3>, <cell 'Sheet'.A4>, <cell 'Sheet'.A5>) >>> >>> cells = sheet['A':'D'] >>> print(cells) ((<cell 'Sheet'.A1>, <cell 'Sheet'.A2>, <cell 'Sheet'.A3>, <cell 'Sheet'.A4>, <cell 'Sheet'.A5>), (<cell 'Sheet'.B1>, <cell 'Sheet'.B2>, <cell 'Sheet'.B3>, <cell 'Sheet'.B4>, <cell 'Sheet'.B5>), (<cell 'Sheet'.C1>, <cell 'Sheet'.C2>, <cell 'Sheet'.C3>, <cell 'Sheet'.C4>, <cell 'Sheet'.C5>), (<cell 'Sheet'.D1>, <cell 'Sheet'.D2>, <cell 'Sheet'.D3>, <cell 'Sheet'.D4>, <cell 'Sheet'.D5>))
同样,我们可以通过指定数字范围来访问整行。要获取前三行的所有单元格,可以这样写:
>>> cells = sheet[1:3] >>> print(cells) ((<cell 'Sheet'.A1>, <cell 'Sheet'.B1>, <cell 'Sheet'.C1>, <cell 'Sheet'.D1>), (<cell 'Sheet'.A2>, <cell 'Sheet'.B2>, <cell 'Sheet'.C2>, <cell 'Sheet'.D2>), (<cell 'Sheet'.A3>, <cell 'Sheet'.B3>, <cell 'Sheet'.C3>, <cell 'Sheet'.D3>))
我们可以使用表格的 iter_rows() 和 iter_cols() 方法,而不是指定范围来访问一系列单元格的值。两种方法都接受相同的可选参数:
min_row最小行的索引max_row最大行的索引min_col最小列索引max_col最大列索引values_only是否只返回单元格值
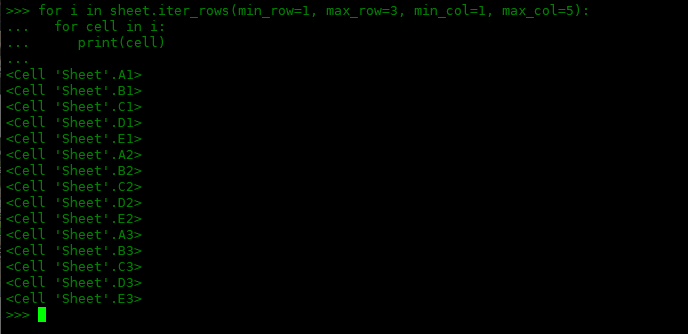
在带有 min_row/max_row 和 min_col/max_col 参数的这两种方法中,我们指定了应该进行迭代的行和列的范围。两者的区别在于 iter_rows() 返回按行组织的单元格,其中 iter_cols() 返回按列组织的单元格。让我们看一些实际的例子。假设我们要遍历从第一列到第五列的前三行,并希望获得按行组织的单元格。这是我们将运行的内容:
>>> for i in sheet.iter_rows(min_row=1, max_row=3, min_col=1, max_col=5): ... for cell in i: ... print(cell) ... <cell 'Sheet'.A1> <cell 'Sheet'.B1> <cell 'Sheet'.C1> <cell 'Sheet'.D1> <cell 'Sheet'.E1> <cell 'Sheet'.A2> <cell 'Sheet'.B2> <cell 'Sheet'.C2> <cell 'Sheet'.D2> <cell 'Sheet'.E2> <cell 'Sheet'.A3> <cell 'Sheet'.B3> <cell 'Sheet'.C3> <cell 'Sheet'.D3> <cell 'Sheet'.E3>
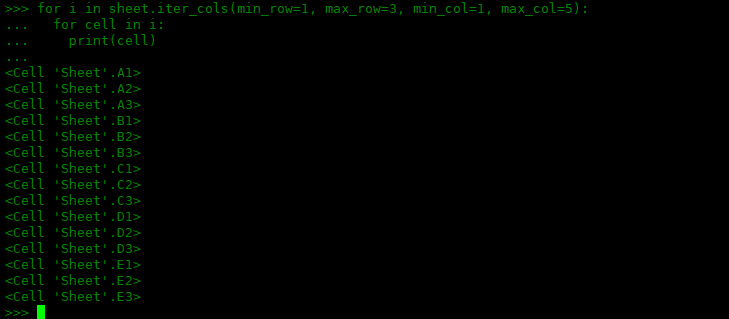
为了获得相同的单元格,这次按列循环,我们将使用相同的参数传递给 iter_cols() 方法:
>>> for i in sheet.iter_cols(min_row=1, max_row=3, min_col=1, max_col=5): ... for cell in i: ... print(cell) ... <cell 'Sheet'.A1> <cell 'Sheet'.A2> <cell 'Sheet'.A3> <cell 'Sheet'.B1> <cell 'Sheet'.B2> <cell 'Sheet'.B3> <cell 'Sheet'.C1> <cell 'Sheet'.C2> <cell 'Sheet'.C3> <cell 'Sheet'.D1> <cell 'Sheet'.D2> <cell 'Sheet'.D3> <cell 'Sheet'.E1> <cell 'Sheet'.E2> <cell 'Sheet'.E3>
在本教程中,我们学习了如何使用 Python openpyxl 库处理 Excel 表格文件。我们看到了如何在内存中或从文件中创建工作簿,如何检索、创建、复制、移动和删除工作表,如何访问单元格和单元格范围,以及如何遍历行和列。
本文原创地址:https://www.linuxprobe.com/openpyxl-excel-usage.html编辑:逄增宝,审核员:逄增宝







