| 导读 | 如果你从事数据科学研究有一段时间了,那么pandas, scikit-learn seaborn和matplotlib这些库你都应该非常的熟悉。 |

如果您想要扩展您的视野,学习一些更少见但同样有用的库。在本文中,我将向您展示一些不太为人所知的但是却非常好用的python库。
如果你过去一直在构建一些有监督的机器学习模型,你就会知道目标变量中的类别不平衡可能是一个大问题。这是因为在少数类中没有足够的例子来让算法学习模式。
一个解决方案是创建一些合成样本,通过使用例如SMOTE(合成少数群体过采样技术)来增加少数群体类的学习。
幸运的是,imbalance-learn库将帮助您在任何不平衡数据集上实现这一技术。
您可以通过在终端上执行以下命令来安装imbalance-learn库。
pip install imbalanced-learn
为了演示如何平衡数据集,我们将使用sklearn下载乳腺癌数据集。
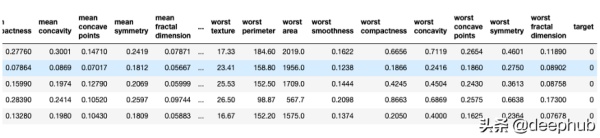
from sklearn.datasets import load_breast_cancer import pandas as pddata = load_breast_cancer() df = pd.DataFrame(data.data, columns=[data.feature_names]) df[‘target’] = data[‘target’] df.head()
下面看目标变量的分布。
df.target.value_counts()
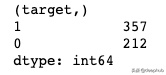
数据集确实是均匀分布的,尽管它不是非常不平衡:我们有357名乳腺癌患者和212名健康患者。
我们看看能不能让它更平衡一点。我们将使用SMOTE对0类进行过采样。
from imblearn.over_sampling import SMOTE oversample = SMOTE() X_oversample, y_oversample = oversample.fit_resample(data.data, data.target) pd.Series(y_oversample).value_counts()
如你所见,数据集现在已经完全平衡了。每个类有357个实例。作为我们操作的结果,创建了145个人工实例。
这是另一个很棒的库,专门用来建立统计模型。我通常用它来拟合线性回归
它真的很容易使用,你可以马上得到很多关于模型的信息,比如R2 BIC、AIC、置信度和它们相应的p值。当使用scikit-learn的线性回归时,这些信息更难以获取。
让我们看看如何使用这个库来适应线性回归模型。让我们先下载一个波士顿房价数据集。
from sklearn.datasets import load_boston import pandas as pd data = load_boston() df = pd.DataFrame(data.data, columns=[data.feature_names]) df[‘target’] = data[‘target’] df.head()
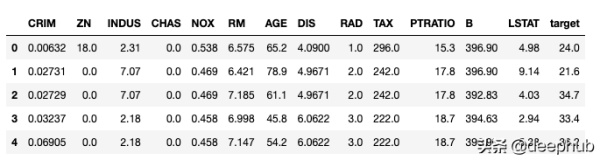
上面是我们的数据集的前五行。有13个特征,我们可以看到一个目标变量是一个连续的数字。这是一个完美的回归数据集。
现在让我们使用pip安装统计模型库
pip install statsmodels
现在,我们可以使用以下代码尝试将线性回归模型与我们的数据相匹配。
import statsmodels.api as sm X = sm.add_constant(df.drop(columns=[‘target’])) # adding a constant model = sm.OLS(df.target, X).fit() predictions = model.predict(X) print_model = model.summary() print(print_model)
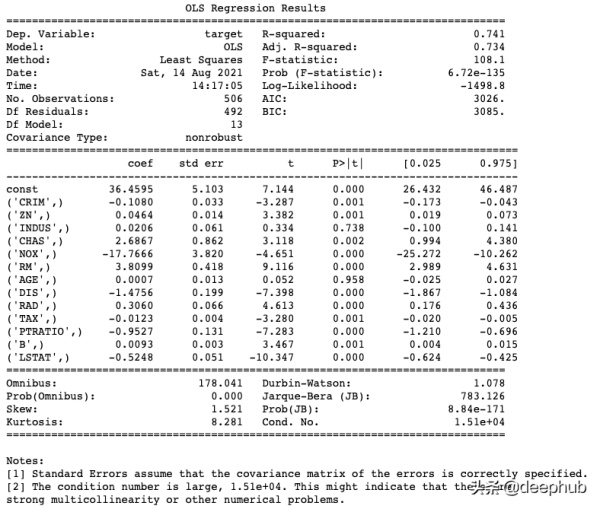
我们刚刚将一个线性回归模型拟合到这个数据集上,并打印出了该模型的详细摘要。您可以很容易地阅读所有重要信息,在必要时重新调整功能,并重新运行模型。
我发现与scikit-learn版本相比,使用statsmodels进行回归更容易,因为我需要的所有信息都在这个简短的报告中。
missingno是另一个有用的库。它可以帮助您可视化缺失值的分布。
您可能已经习惯使用isnull()函数检查pandas中的缺失值。这可以帮助您获取每列缺失值的数量,但不能帮助您确定它们的位置。这正是missingo变得有用的时候。
你可以使用下面的命令安装库:
pip install missingno
现在,让我们演示如何使用missingo来可视化缺失的数据。为了做到这一点,我们将从Kaggle下载预期寿命数据集。
然后可以使用read_csv()函数加载数据集,然后从missingno库调用matrix()函数。
import pandas as pd import missingno as msno df = pd.read_csv(‘Life Expectancy Data.csv’) msno.matrix(df)

可以看到缺失值的位置。如果怀疑丢失的值位于某个特定位置或遵循某个特定模式,那么它将非常有用。
以上三个库非常的有用,通过使用它们可以简化我们的操作,提高我们的工作效率。
原文来自:https://developer.51cto.com/art/202108/678215.htm
本文地址:https://www.linuxprobe.com/python-3-libraries.html编辑:清蒸github,审核员:逄增宝
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/