

| 导读 | 在Oracle数据库的世界里,Redo Log是一个非常核心的存在,通过Redo日志,Oracle实现了数据变更的延迟写出,通过日志的顺序写推延了数据块离散写的性能影响,从而实现了高效率运作。 |
Redo Log首先在Buffer中生成,然后写出到磁盘上的Redo Log File – 重做日志文件,那么如何配置日志文件就成为数据库优化和健康巡检的重要内容之一。如果日志文件过小,就会出现重做日志频繁切换,检查点不能及时完成等问题,影响到数据库的正常运行。
最常见的,如果在告警日志中看到 Checkpoint not complete 的提示,就意味着存在日志切换重用时的阻塞。如果频繁出现,那么就必须采取主动的优化措施,如加大日志文件大小、增加日志组等。
在白求恩 – Bethune 智能巡检平台上,我们专门设定了于此有关的检查分析项目,帮助用户及时简单的剖析在日志设置上可能存在的问题。
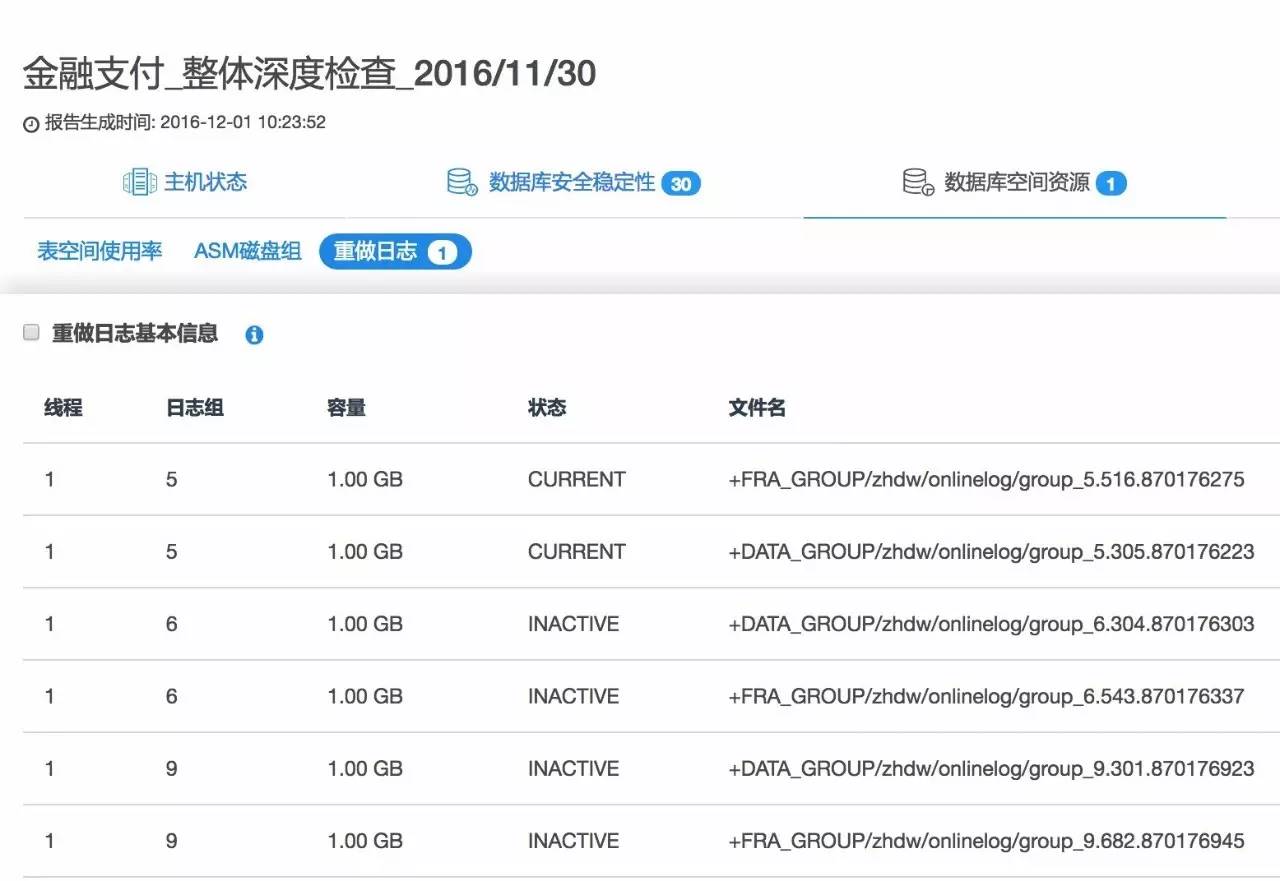
在【数据库空间资源 – 重做日志】分析项,可以找到和Redo相关的分析项:
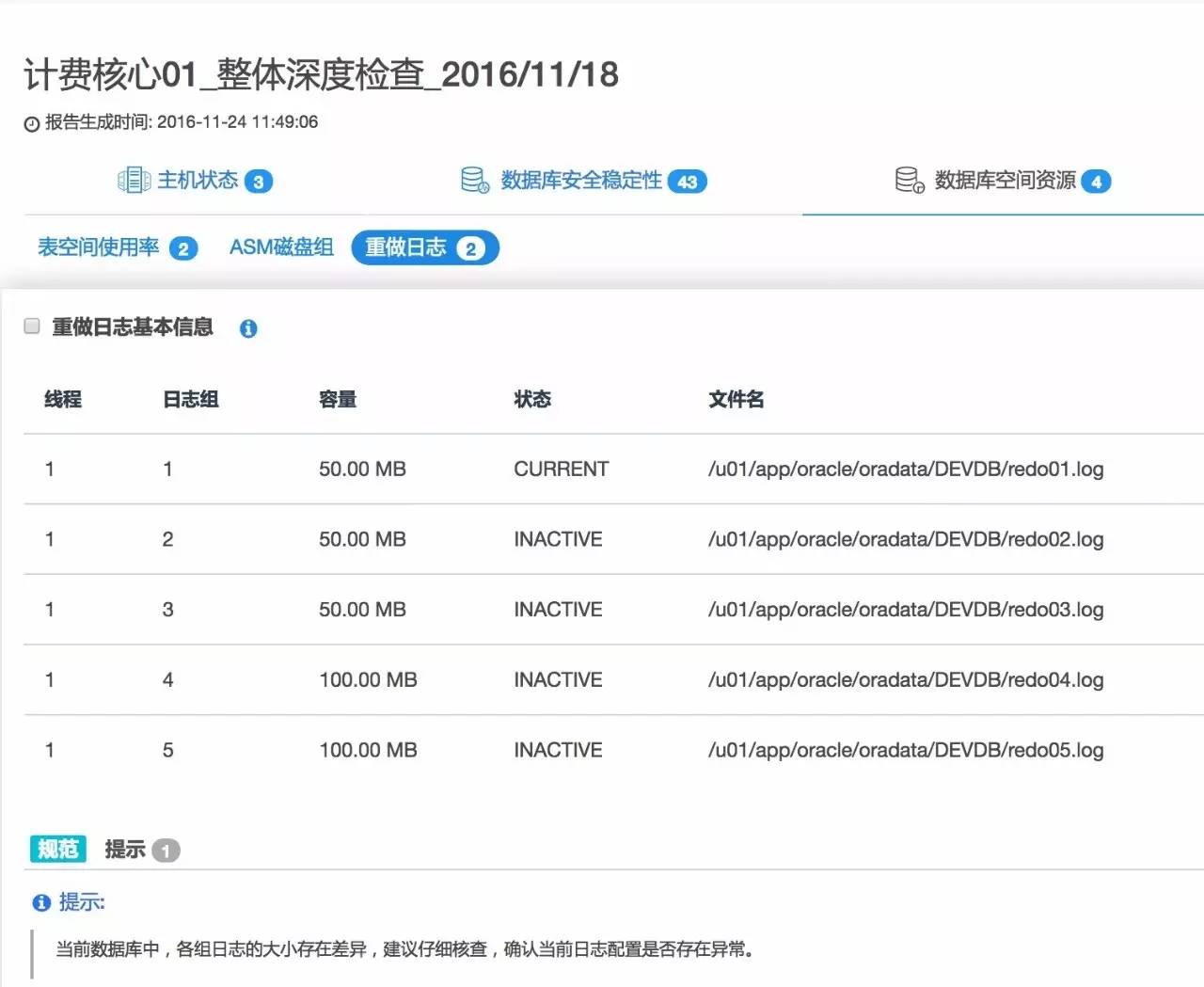
如果在日志设置上存在问题,Bethune会给出分析提示,如以下数据库的日志组大小不一致,三组日志大小是50M,另外两组日志大小是100M,这是不规范的配置,可能来自于某次临时的日志组增加,事实上需要DBA进行审视和整改:
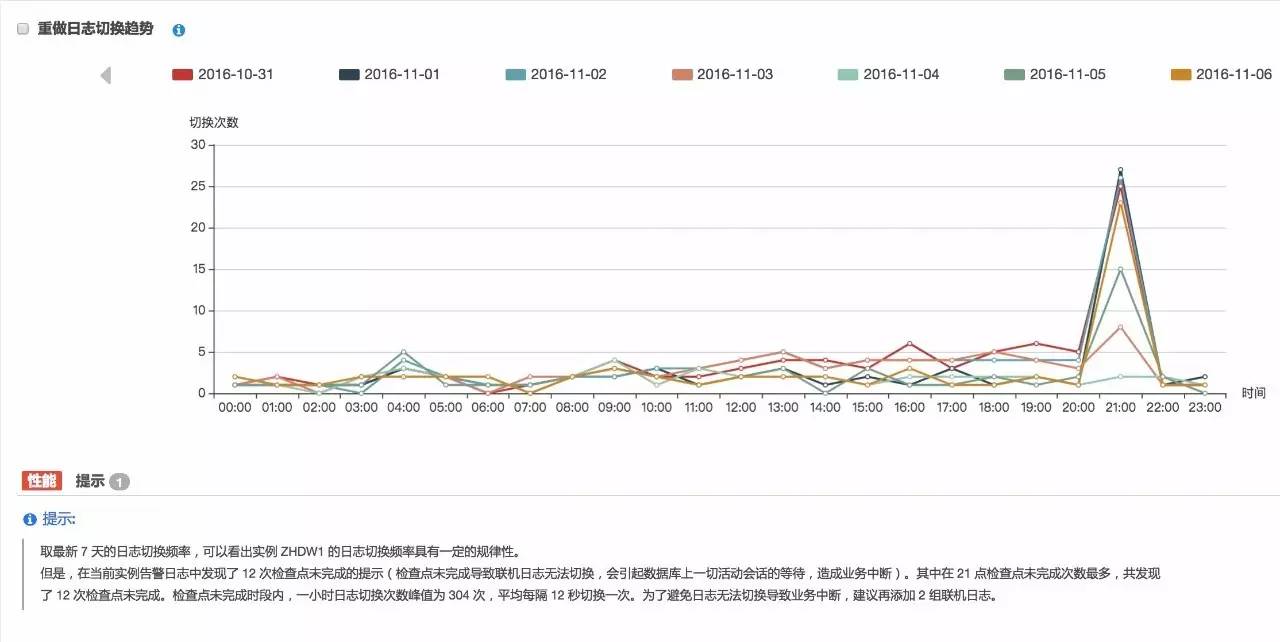
对于日志切换频率,Bethune 给出了详细的趋势分析,多日数据的趋势作为对比展现,可以清晰的帮助我们看到系统的日志变化和波动点:
将鼠标移动到峰值处,我们可以看到在每日的21:00,是数据库几种的日志产生高峰,在该时段可能存在批处理作业:
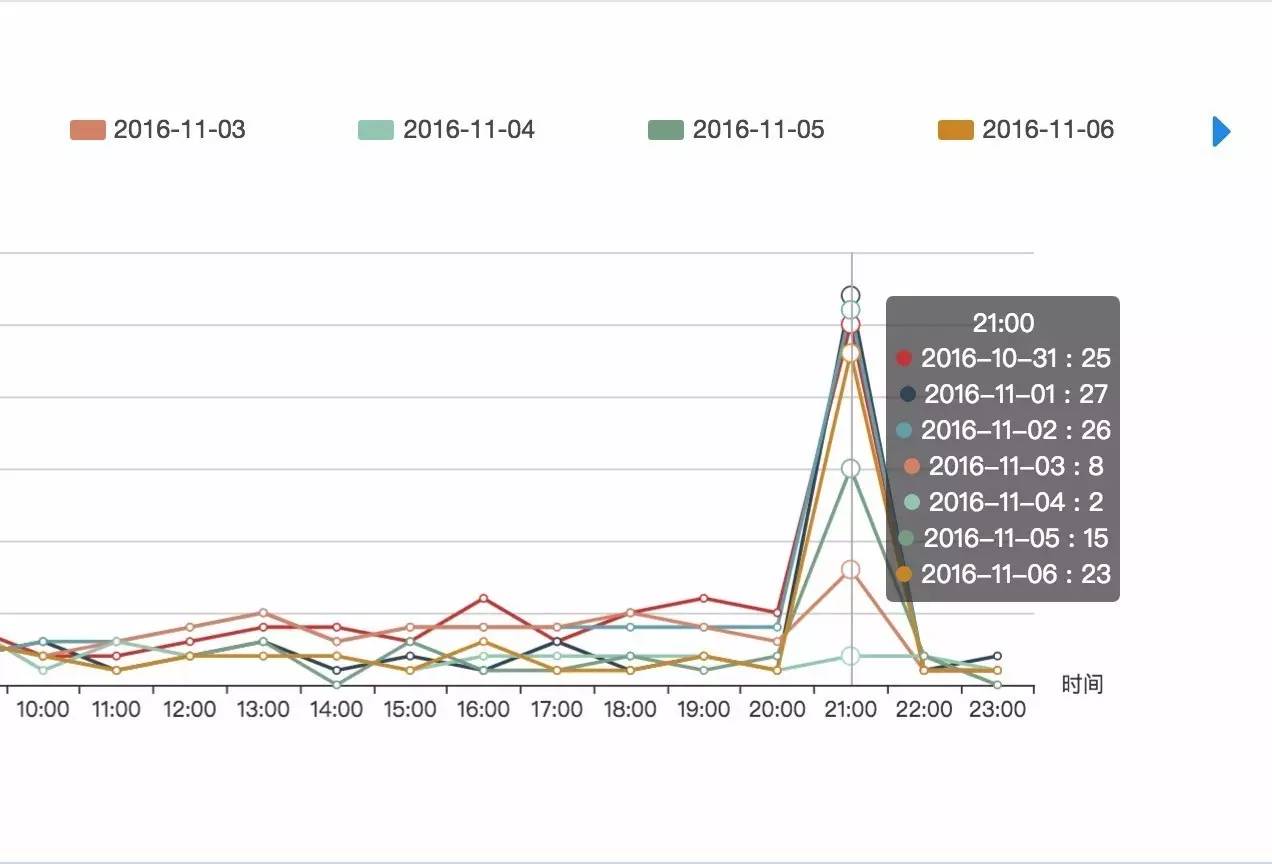
通过点选具体的日期,我们可以在趋势图保留两个日期,分析其业务变化在日志生成上的改变,如图的两个日期,日志切换的波动非常吻合,这说明这个业务系统的运行是非常规律的:
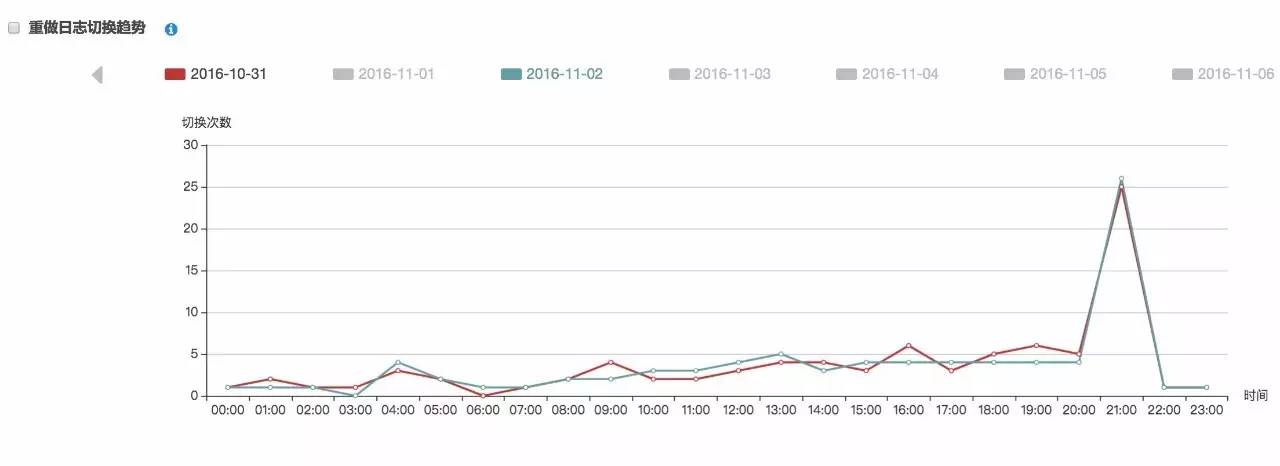
当然,如果伴随着日志切换,数据库告警日志中出现了『检查点未完成』等待,在分析提示中会以性能标签提示出来,在这种情况下,我们通常需要进行日志配置的调整以消除这类问题:
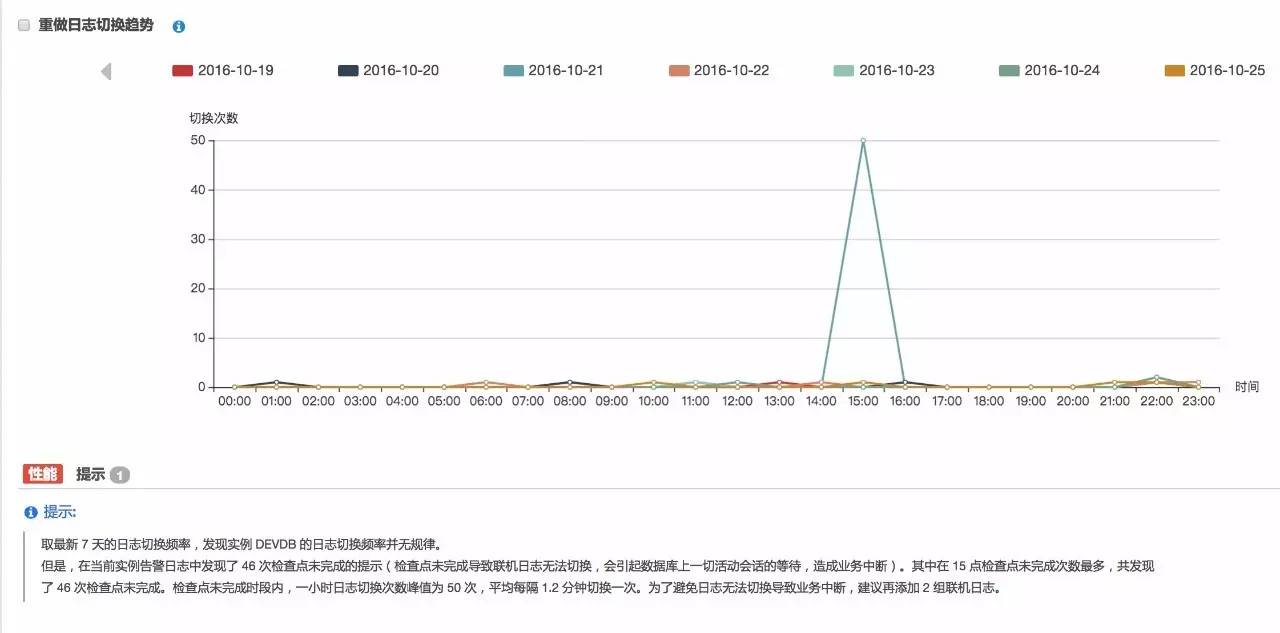
以上这段提示给出了非常具体的建议:
在当前实例告警日志中发现了 46 次检查点未完成的提示(检查点未完成导致联机日志无法切换,会引起数据库上一切活动会话的等待,造成业务中断)。其中在 15 点检查点未完成次数最多,共发现了 46 次检查点未完成。检查点未完成时段内,一小时日志切换次数峰值为 50 次,平均每隔 1.2 分钟切换一次。为了避免日志无法切换导致业务中断,建议再添加 2 组联机日志。
Bethune 的日志分析,一个页面帮你了解日志组的配置和切换频度,以及数据库的相应性能表征,Oracle数据库无微不至的智能诊断,从白求恩开始!
原文来自:http://www.yunweipai.com/archives/18363.html
本文地址:https://www.linuxprobe.com/redo-log.html编辑员:郭建鹏,审核员:逄增宝
本文原创地址:https://www.linuxprobe.com/redo-log.html编辑:roc_guo,审核员:暂无







