| 导读 | 国家超算天津中心在第七届世界智能大会上发布了天河百亿亿级智能计算开放创新平台和国产中文大模型 —— 天河天元。 |
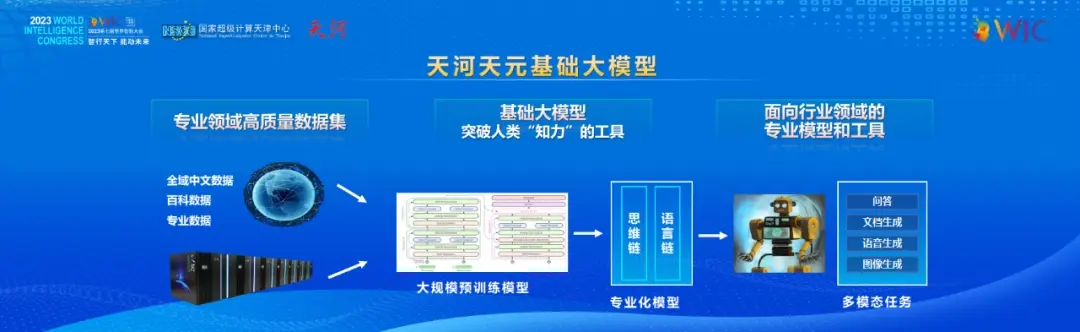
中文大语言模型的数据集非常稀缺。国家超算天津中心搜集整理了网页数据、各种开源训练数据、中文小说数据、古文数据、百科数据、新闻数据,以及专业领域的中医、医药、问诊、法律等多种数据集,训练数据集总 token 数达到 350B,训练打造了自己的中文语言大模型 —— 天河天元大模型。

天河新一代超级计算机实现了从硬件到软件环境全面自主的信息技术应用创新,官方也在展区展示了天河新一代超级计算机上采用的计算芯片、主板等核心技术。
据悉,“天河 E 级智能计算开放创新平台” 将带来突破百亿亿次的跨模态的超级计算算力,支撑传统的科学工程计算,并服务智能混合计算,打造全方位的算力赋能创新和数字经济高质量发展载体。
未来,国家超算天津中心还将在 “天河天元大模型” 的基础上启动深度训练面向医疗、工业、法律等领域的专业模型。未来大模型将在深度学习平台的支撑下成为产业智能化基座。
原文来自:https://www.oschina.net/news/241824
本文地址:https://www.linuxprobe.com/token-linux-hangul.html编辑:xiangping wu,审核员:清蒸github
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/