

| 导读 | 链式调用是我们在写程序时候的一般流程,为了完成一个整体功能,会将其拆分成多个函数(或子模块),比如模块A调用模块B,模块B调用模块C,模块C调用模块D。 |
最近小L会听到很多学员说,在面试大型互联网公司的时候,很可能会被问到消息队列的问题:
-
在何种场景下使用了消息中间件?
为什么要在系统里引入消息中间件?
如何实现幂等?
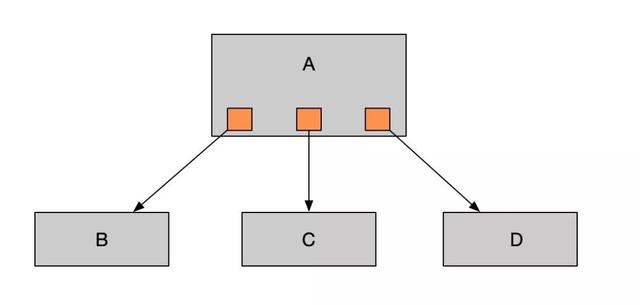
链式调用是我们在写程序时候的一般流程,为了完成一个整体功能,会将其拆分成多个函数(或子模块),比如模块A调用模块B,模块B调用模块C,模块C调用模块D。但在大型分布式应用中,系统间的RPC交互繁杂,一个功能背后要调用上百个接口并非不可能,这种架构有如下几个劣势:
1、 这些接口之间耦合比较严重,每新增一个下游功能,都要对上有的相关接口进行改造;举个例子:假如系统A要发送数据给系统B和C,发送给每个系统的数据可能有差异,因此系统A对要发送给每个系统的数据进行了组装,然后逐一发送;当代码上线后,新增了一个需求:把数据也发送给D。此时就需要修改A系统,让他感知到D的存在,同时把数据处理好给D。在这个过程中你会看到,每接入一个下游系统,都要对A系统进行代码改造,开发联调的效率很低。其整体架构如下图:
2、 面对大流量并发时,容易被冲垮。每个接口模块的吞吐能力是有限的,这个上限能力如果堤坝,当大流量(洪水)来临时,容易被冲垮。
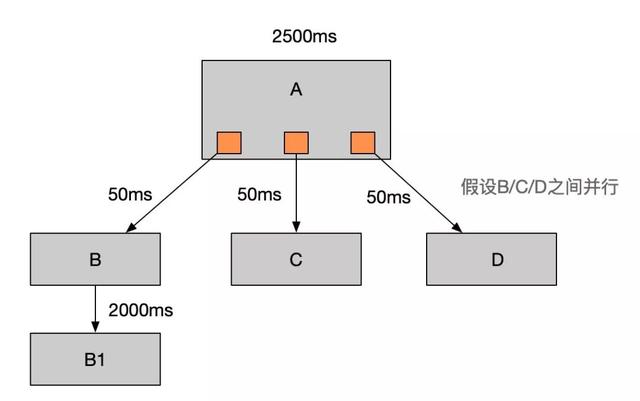
3、 存在性能问题。RPC接口基本上是同步调用,整体的服务性能遵循“木桶理论”,即链路中最慢的那个接口。比如A调用B/C/D都是50ms,但此时B又调用了B1,花费2000ms,那么直接就拖累了整个服务性能。
根据上述的几个问题,在设计系统时可以明确要达到的目标:
-
1、要做到系统解耦,当新的模块接进来时,可以做到代码改动最小;
2、设置流量缓冲池,可以让后端系统按照自身吞吐能力进行消费,不被冲垮;
3、强弱依赖梳理,将非关键调用链路的操作异步化,提升整体系统的吞吐能力,比如上图中A、B、C、D是让用户发起付款,然后返回付款成功提示的几个关键流程,而B1是通知付款后通知商家发货的模块,那么实质上用户对B1完成的时间容忍度比较大(比如几秒之后),可以将其异步化。
在现在的系统视线中,MQ消息队列是普遍使用的,可以完美的解决这些问题的利器。下图是使用了MQ的简单架构图,可以看到MQ在最前端对流量进行蓄洪,下游的系统ABC只与MQ打交道,通过事先定义好的消息格式来解析。

引入MQ之后的系统架构、交互方式与最初的链式调用架构非常不同,虽然可以解决上文提到的问题,但也要充分理解其原理特性来避免其带来的副作用,这里以消息队列如何保证“消息的可靠投递”为切入点,来看看MQ的实现方式。
-
1.Client发送消息给MQ
2.MQ将消息持久化后,发送Ack消息给Client,此处有可能因为网络问题导致Ack消息无法发送到Client,那么Client在等待超时后,会重传消息;
3.Client收到Ack消息后,认为消息已经投递成功。
-
1.MQ将消息push给Client(或Client来pull消息)
2.Client得到消息并做完业务逻辑
3.Client发送Ack消息给MQ,通知MQ删除该消息,此处有可能因为网络问题导致Ack失败,那么Client会重复消息,这里就引出消费幂等的问题;
4.MQ将已消费的消息删除
原文来自:http://developer.51cto.com/art/201910/604224.htm
本文地址:https://www.linuxprobe.com/java-message-queue.html编辑:KSJXAXOAS,审核员:逄增宝
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/






