

| 导读 | Meta 宣布了一项在语音生成领域的突破性成果:Voicebox。这是一个在各方面都表现非常先进的语音生成 AI 模型,它能够通过上下文学习执行语音生成任务,如编辑、采样和风格转换等,而无需专门训练。 |
与其他生成语音的 AI 需要使用精心准备的训练数据对每项任务进行特定训练不同。Voicebox 使用一种新方法来仅从原始音频和随附的转录中学习。这种方法提高了模型的灵活性,能够更好地适应各种任务。
Voicebox 采用非自回归的流匹配模型,它被训练用于填充语音,给定音频上下文和文本,并在超过 50000 小时的未经过滤或增强的语音上进行训练。类似于 GPT,Voicebox 可以通过上下文学习执行许多不同的任务,但它更灵活,因为它还可以根据未来的上下文进行条件化。
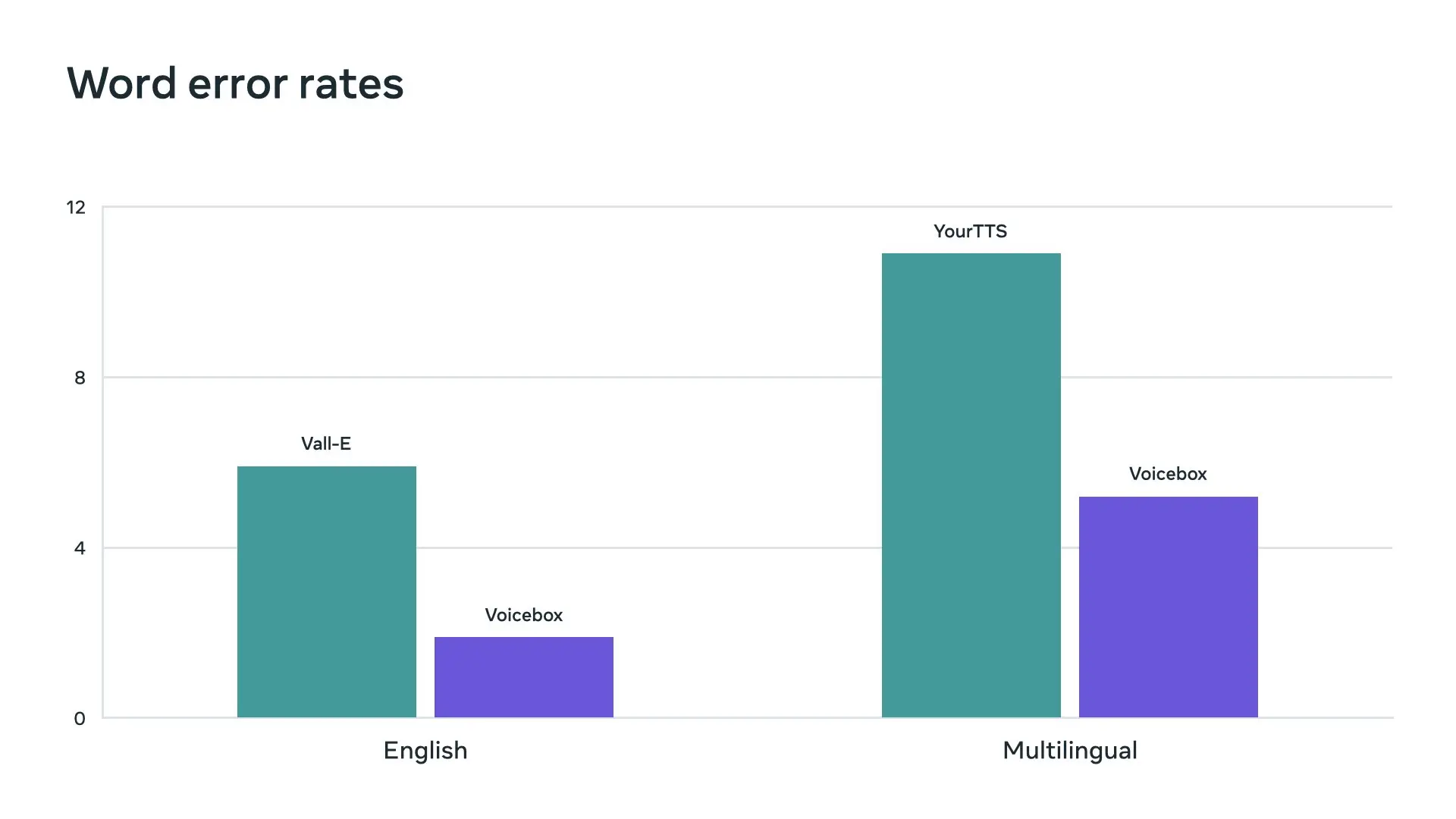
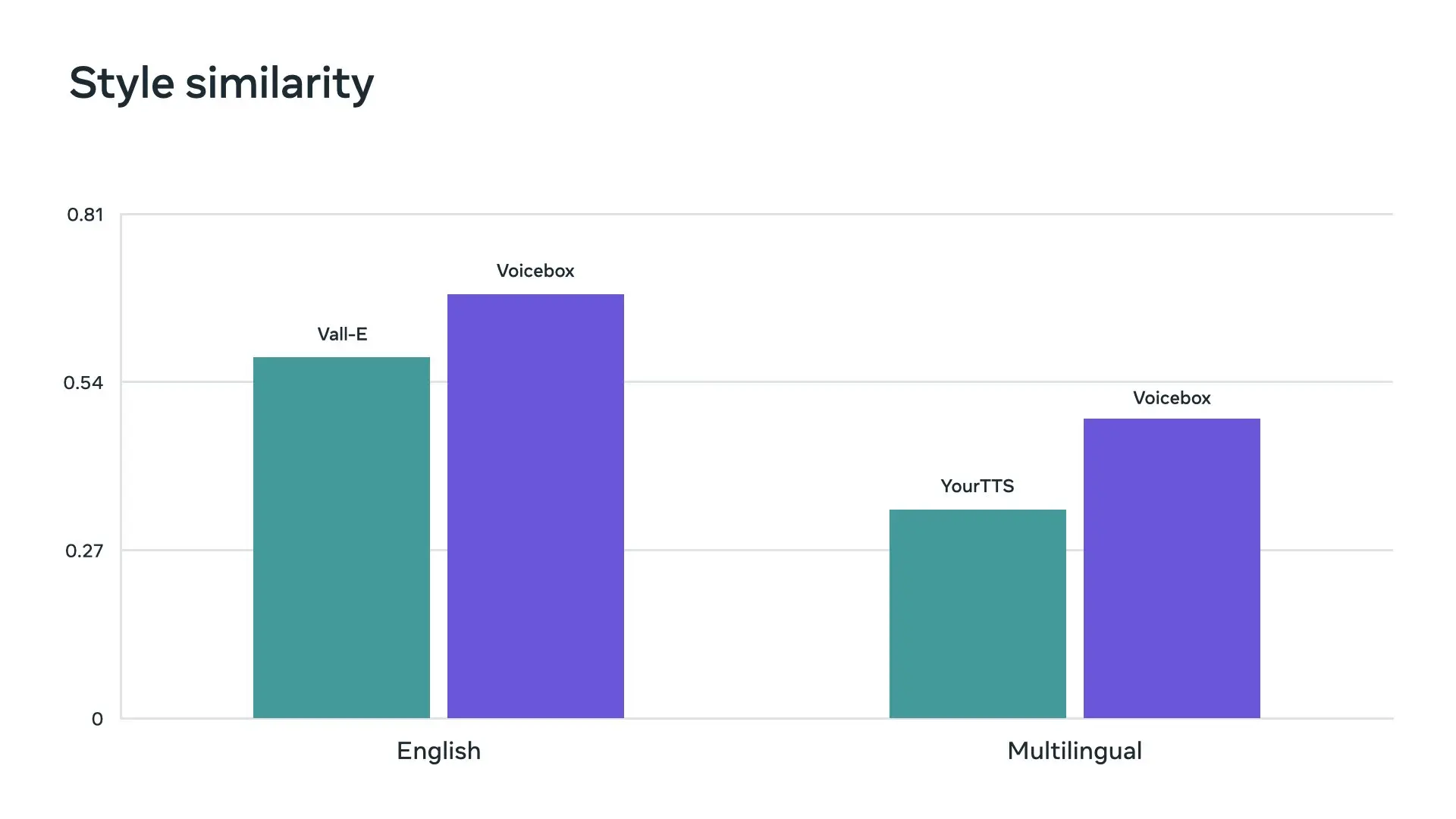
Voicebox 模型具有多种用途。它可以用于单语言或跨语言的零样本文本到语音合成、噪声去除、内容编辑、风格转换和多样性样本生成。特别地,Voicebox 在可理解性(5.9% 对 1.9% 的单词错误率)和音频相似度(0.580 对 0.681)方面优于当前最先进的英语模型 VALL-E,同时速度比它快 20 倍。
对于跨语言风格迁移,Voicebox 优于 YourTTS,将平均单词错误率从 10.9% 降低到 5.2%,并将音频相似度从 0.335 提高到 0.481。
目前可以在 voicebox.metademolab.com 查看模型演示。
由于潜在的滥用风险,目前并未公开提供 Voicebox 模型或代码。尽管如此,他们仍然分享了音频样本和一篇研究论文,详细介绍了他们的方法和所取得的结果。
原文来自:https://www.oschina.net/news/245895/meta-voicebox-generative-ai-model-speech
本文地址:https://www.linuxprobe.com/meta-voicebox-linux.html编辑:xiangping wu,审核员:清蒸github
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/







