

企业在采用容器的同时,也将容器的监控问题放在了比较优先的位置上,不少企业使用普罗米修斯(Prometheus)监控容器和微服务,对于规模企业通常会更加激进,所以当他们规模部署时将面临扩展的挑战。

监控整体环境过去相对简单,企业具有一定数量的静态物理服务器和虚拟机,以及数量有限的指标。现在由于容器以及向微服务架构的迁移,要跟踪的实体数量激增。
容器的数量不断增加,有时每台机器上有数百台,而新的机器也在增加,并且与Kubernetes等编排工具一起使用时,使得容器的寿命可能非常短,使得跟踪它们变得更加困难,并且如果不小心的话,它们可能会造成很多问题。
随着环境的复杂性和分布的增加,需要监控的实体数量也在增加。此外,你可能希望监控更多属性,来确保对所发生的事情有准确的了解,或者在进行故障排除或事件响应的情况下,可以了解所发生的事。在这些短暂的环境中,故障的排除尤其成问题,因为当你想了解问题的根本原因时,通常有问题的资源已经停用,这意味着监控解决方案必须提供一种存储足够的历史记录来进行取证的方法。
当需要进行云监控时,IT团队越来越多地倾向于Prometheus,它是由云原生计算基金会开源的项目。Prometheus已成为开发人员在云原生环境中收集和理解指标的首选监控工具。它由一个大型社区支持,有超过700多家企业贡献者。
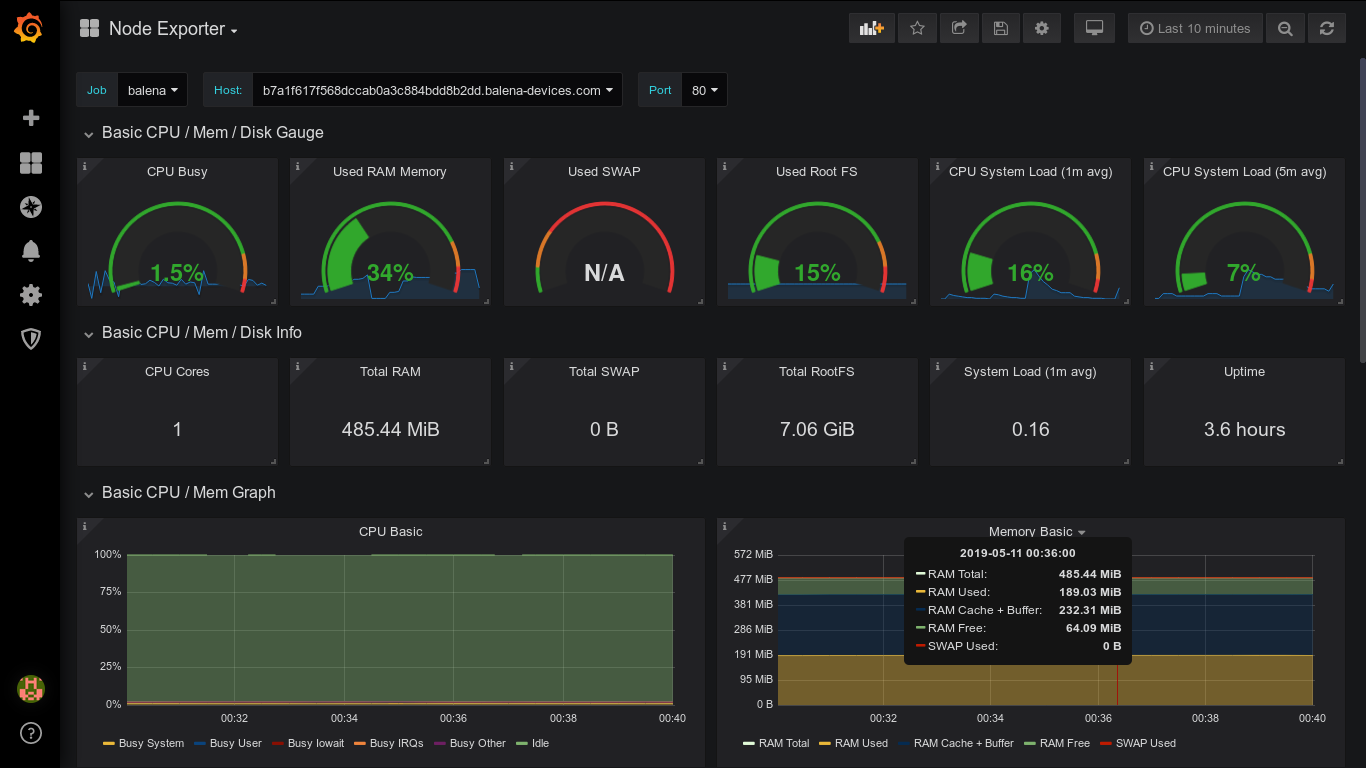
随着环境的发展,需要跟踪的时间序列数据数量激增,在某个特定点上,单个Prometheus实例将无法跟上。直接的选择是在整个企业中运行一批Prometheus服务器,但这也带来了一些挑战。例如,管理和联合数十或数百个Prometheus服务器上的数据并不容易。类似地,确定企业工作流、单点登录、基于角色的访问控制以及遵守SLA或遵从性也不是容易的问题。随着应用程序的增长,在不中断开发人员工作的情况下操作一个包罗万象的监控解决方案将成为一个巨大的可管理性和可靠性问题。
为了解决这个问题,企业采用了一些方法。
简单的第一步是为每个名称空间或每个集群使用单独的Prometheus服务器。这种方法显然很难扩展到某个特定的点,除此之外,它还有创建大量断开连接的数据孤岛的缺点。这使得故障排除变得很麻烦,因为大多数问题将跨越多个服务/团队/集群。不仅很难在每个环境中找到相同的度量标准,而且还必须将数据结合起来,试图理解正在发生的事情。
另一种常见的方法是使用如Cortex或thanos等开源工具来联合多个Prometheus服务器。它们是功能强大的工具,能够以集中的方式查询服务器,收集数据,然后在单个仪表板中共享数据。然而,与任何数据密集型分布式系统一样,它们需要大量的技能和资源来操作。
对于那些从Prometheus开始,然后寻找商业解决方案来提供整体监控的企业来说,重要的是不要失去所有在Prometheus标准化的开发工作,如仪表盘、警报等工作。然而,这不是你应该考虑的唯一,下面的这些因素或许对你有帮助。
企业选择的云供应商、工具或SaaS解决方案需要能够使用任何可产生Prometheus指标的数据,无论是本地Kubernetes还是任何的云服务。Prometheus指标相对来说比较琐碎,但不要忽略一些小事情,例如将指标提取到存储中或扩充数据时能够重新标注指标,这样对环境更加有意义。这些事情叠加,在使用大量收集的数据方面会产生很大的不同。
Prometheus查询语言用于提取Prometheus存储的信息。PromQL能够询问有关指标,例如特定服务或特定用户。它还允许聚合或分段数据,例如可以使用它在应用程序基础上显示所有容器的CPU利用率,或者仅显示Cassandra容器的数据,并将其显示为每个集群的单个值。所以,PromQL解锁了Prometheus的真正价值;因此,在不完全支持PromQL的产品中加入Prometheus度量标准会破坏使用Prometheus的目的。
要真正与Prometheus兼容,解决方案必须是可热插拔的,以便能够与现有的仪表板、警报和脚本一起工作。例如,许多使用Prometheus的企业使用Grafana作为仪表盘。这个开源工具与Prometheus很好地集成在一起,包括在查询级别,并且可以用于生成一系列有用的图表和指示板。因此,那些声称与Prometheus兼容的商业产品应该与Grafana这样的工具兼容。仅仅说解决方案可以在Grafana中查看数字是不够的。需要能够按原样提取现有的Grafana仪表板,并将它们重新应用于商业解决方案中的数据。

访问控制是评估工具时应该考虑的另一个安全问题。通过使用行业标准协议(包括LDAP、谷歌Oauth、SAML和OpenID)来确保用户身份验证的安全,企业能够通过基于服务的访问控制来隔离和保护资源。
Kubernetes简化了容器化应用程序和微服务的部署、伸缩和管理。这有助于保持服务的正常运行,但是要识别和解决底层问题,比如性能下降、失败的部署和连接错误,需要能够收集和可视化来自生产环境的深入基础设施、应用程序和性能数据。不能同时访问实时信息和上下文数据,就几乎不可能在环境中关联度量,从而更快地解决问题。
最后,如果你正在寻找一个商业答案来帮助解决Prometheus可伸缩性问题,请确保它支持所有级别的警报。实现这一点的关键是完全支持警报管理器功能,这反过来需要100%的和PromQL兼容性。
原文来自:https://cloud.51cto.com/art/202009/625465.htm
本文地址:https://www.linuxprobe.com/prometheus-6-jiankong.html编辑:问题终结者,审核员:逄增宝
Linux命令大全:https://www.linuxcool.com/
Linux系统大全:https://www.linuxdown.com/
红帽认证RHCE考试心得:https://www.rhce.net/







